# !pip install pandas geopandas pyarrow scikit-learn clustergram umap-learn seaborn plotly matplotlib numpy keplergl openai
# from google.colab import output
# output.enable_custom_widget_manager()Creating Cutting-Edge Geodemographic Classifications from Scratch in Python
Workshop Content
This notebook contains the full workflow for producing a geodemographic classification from scratch in python using k-means clustering.
- Data Access and Processing:
- Access UK Census data and process using Pandas.
- Select a specific region of interest (e.g., Liverpool City Region, Greater Manchester, Greater London).
- Census Data Analysis and Variable selection:
- Select relevant Census variables for clustering.
- Standardise variables.
- Perform correlation & variance analysis to identify potentially redundant variables.
- Alternative variable selection methods (e.g., PCA, Autoencoders).
- Clustering:
- Determine optimal number of clusters using Clustergrams.
- Apply K-Means clustering to classify areas based on selected variables.
- Perform top-down hierarchical clustering to divide clusters into subgroups.
- Analytical Techniques:
- Use UMAP (Uniform Manifold Approximation and Projection) to visualise high-dimensional embeddings in 2D.
- Visualisation and Communication:
- Visualise clusters and subclusters using Kepler.gl for interactive mapping.
- Explore cluster characteristics using summary statistics and index scores.
- Export results to various formats (GeoPackage, Parquet) for use in GIS software.
- Cluster Naming with LLMs:
- Use Large Language Models (LLMs) to generate descriptive names and summaries for clusters based on their characteristics.
What are Geodemographics?
Geodemographics are a method of classifying geographic areas based on the characteristics of their populations. It involves grouping areas with similar demographic, socio-economic, and lifestyle attributes into distinct categories or clusters. These classifications help in understanding the spatial distribution of different population segments and are widely used in various fields such as marketing, urban planning, public health, and social research. For more information on geodemographics in the UK and the US see: (Alexander D. Singleton and Spielman 2014).
Singleton, Alexander D., and Seth E. Spielman. 2014. “The Past, Present, and Future of Geodemographic Research in the United States and United Kingdom.” The Professional Geographer 66 (4): 558–67. https://doi.org/10.1080/00330124.2013.848764.
Geodemographic classifications are typically created using statistical techniques such as cluster analysis, in particular k-means clustering. That is the method we will use in this workshop.
Running the Notebook yourself
The code used to generate this notebook is available on GitHub. Instructions for setting up the environment and downloading the data are provided in the README file.
Install Required Packages in Colab
If you are using Google Colab, you will need to install the required packages in the Colab environment. This also enables the custom widget manager required for Kepler.gl to work in Colab. You can do this by uncommenting and running the following code cell in the notebook:
Import the necessary libraries and packages.
import os
import pandas as pd
import numpy as np
import geopandas as gpd
from sklearn.cluster import KMeans
import umap.umap_ as umap
from clustergram import Clustergram
import openai
import matplotlib.pyplot as plt
from matplotlib import colors as mcolors
from keplergl import KeplerGl
import plotly.express as px
import seaborn as sns
import json
#set a random seed for reproducibility
random_seed = 507
#check that outputs directories exists (if not create it), this is important if you are running the notebook in colab
if not os.path.exists('outputs'):
os.makedirs('outputs')
if not os.path.exists('outputs/maps'):
os.makedirs('outputs/maps')
if not os.path.exists('outputs/plots'):
os.makedirs('outputs/plots')
if not os.path.exists('outputs/subclusters'):
os.makedirs('outputs/subclusters')Retrieving and Preparing Data
We will be using Census data from all four UK nations, which are available openly from the respective national statistics agencies (listed below). For this workshop, we will utilise a subset of Census variables that have been unified across the four nations. These variables were used to produce a UK-wide Output Area Classification (OAC) in 2021 (Wyszomierski et al. 2024). We will also need boundary data for the Output Areas (OAs). All the data required can be downloaded from the Geographic Data Service Website link, place the file input_data_1.zip in the same directory as the notebook and it will be unzipped below.
Wyszomierski, Jakub, Paul A. Longley, Alex D. Singleton, Christopher Gale, and Oliver O’Brien. 2024. “A Neighbourhood Output Area Classification from the 2021 and 2022 UK Censuses.” The Geographical Journal 190 (2): e12550. https://doi.org/10.1111/geoj.12550.
Original Data Sources:
- ONS Census 2021 (England & Wales):
- NRS Census 2022 (Scotland):
- NISRA Census 2021 (Northern Ireland):
- ONS Geoportal for boundaries and shapefiles, including clipped EW, Scotland, and Northern Ireland geographies.
#unzip the data if not already done
if not os.path.exists('input_data'):
import zipfile
with zipfile.ZipFile('input_data_1.zip', 'r') as zip_ref:
zip_ref.extractall('./')#Load the census data
variable_df = pd.read_parquet("input_data/uk_census_data.parquet")
#round to 2 decimal places
variable_df = variable_df.round(2)
#look at the shape of the dataset
print(f"Input data shape: {variable_df.shape}")
#look at the first few rows of the dataset
variable_df.head()Input data shape: (239023, 58)| v01 | v02 | v03 | v04 | v05 | v06 | v07 | v08 | v09 | v10 | ... | v51 | v52 | v53 | v54 | v55 | v56 | v57 | v58 | v59 | v60 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | |||||||||||||||||||||
| E00000001 | 262.41 | 0.56 | 7.34 | 19.21 | 31.07 | 36.72 | 1.13 | 67.05 | 14.77 | 2.8 | ... | 27.59 | 42.53 | 14.94 | 6.90 | 1.15 | 4.60 | 1.15 | 1.15 | 0.00 | 6.21 |
| E00000003 | 611.42 | 3.86 | 9.27 | 22.39 | 26.25 | 27.03 | 2.32 | 71.60 | 6.61 | 2.3 | ... | 26.28 | 39.42 | 23.36 | 4.38 | 0.00 | 2.92 | 1.46 | 2.19 | 0.00 | 2.24 |
| E00000005 | 128.20 | 3.60 | 1.80 | 26.13 | 35.14 | 23.42 | 1.80 | 65.77 | 11.71 | 1.8 | ... | 24.24 | 37.88 | 22.73 | 9.09 | 1.52 | 1.52 | 3.03 | 0.00 | 0.00 | 2.86 |
| E00000007 | 19.59 | 0.68 | 2.72 | 53.74 | 19.73 | 8.84 | 2.72 | 40.82 | 25.85 | 6.1 | ... | 27.36 | 33.96 | 27.36 | 0.94 | 2.83 | 3.77 | 0.94 | 1.89 | 0.94 | 0.70 |
| E00000010 | 702.71 | 0.56 | 3.35 | 46.37 | 30.73 | 11.17 | 0.56 | 54.19 | 19.55 | 4.5 | ... | 20.18 | 24.56 | 24.56 | 7.02 | 6.14 | 7.89 | 0.00 | 0.00 | 9.65 | 10.59 |
5 rows × 58 columns
Output Areas
Output Areas (OAs) (Martin 2002) (called data zones in northern ireland and small areas in Scotland) are the smallest geographical units available openly in the UK Census. They are designed to have similar population sizes and to maximize the internal social homogeneity of each unit. Each OA typically contains around 100-200 households. These are the base geographical units used in this classification.
Martin, David. 2002. “Geography for the 2001 Census in England and Wales.” Population Trends, no. 108: 7—15. http://europepmc.org/abstract/MED/12138615.
Spatial Standardisation
The data here has been normalised by the total population of each OA to give a percentage. This is important as OAs can vary in population size, and using raw counts would bias the clustering towards more populous areas. We also include the population density of each OA (population / area in sqkm) as a variable.
variable_df.head()| v01 | v02 | v03 | v04 | v05 | v06 | v07 | v08 | v09 | v10 | ... | v51 | v52 | v53 | v54 | v55 | v56 | v57 | v58 | v59 | v60 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | |||||||||||||||||||||
| E00000001 | 262.41 | 0.56 | 7.34 | 19.21 | 31.07 | 36.72 | 1.13 | 67.05 | 14.77 | 2.8 | ... | 27.59 | 42.53 | 14.94 | 6.90 | 1.15 | 4.60 | 1.15 | 1.15 | 0.00 | 6.21 |
| E00000003 | 611.42 | 3.86 | 9.27 | 22.39 | 26.25 | 27.03 | 2.32 | 71.60 | 6.61 | 2.3 | ... | 26.28 | 39.42 | 23.36 | 4.38 | 0.00 | 2.92 | 1.46 | 2.19 | 0.00 | 2.24 |
| E00000005 | 128.20 | 3.60 | 1.80 | 26.13 | 35.14 | 23.42 | 1.80 | 65.77 | 11.71 | 1.8 | ... | 24.24 | 37.88 | 22.73 | 9.09 | 1.52 | 1.52 | 3.03 | 0.00 | 0.00 | 2.86 |
| E00000007 | 19.59 | 0.68 | 2.72 | 53.74 | 19.73 | 8.84 | 2.72 | 40.82 | 25.85 | 6.1 | ... | 27.36 | 33.96 | 27.36 | 0.94 | 2.83 | 3.77 | 0.94 | 1.89 | 0.94 | 0.70 |
| E00000010 | 702.71 | 0.56 | 3.35 | 46.37 | 30.73 | 11.17 | 0.56 | 54.19 | 19.55 | 4.5 | ... | 20.18 | 24.56 | 24.56 | 7.02 | 6.14 | 7.89 | 0.00 | 0.00 | 9.65 | 10.59 |
5 rows × 58 columns
Short descriptions of the variables used in this example are found in the file census_variable_lookup.csv. The full variable descriptions can be found in the 2021 Census User Guide.
These variables have been selected to provide a broad overview of demographic, socio-economic, and housing characteristics. They cover aspects such as age distribution, household composition, housing type, housing tenure, employment status and education levels.
#load the lookup file which contains variable descriptions.
var_lookup = pd.read_csv("input_data/census_variable_lookup.csv")[["No.","Variable_Name","Domain"]]
var_lookup| No. | Variable_Name | Domain | |
|---|---|---|---|
| 0 | v01 | Usual residents per square kilometre | Demographic |
| 1 | v02 | Aged 4 years and under | Demographic |
| 2 | v03 | Aged 5 - 14 years | Demographic |
| 3 | v04 | Aged 25 - 44 years | Demographic |
| 4 | v05 | Aged 45 - 64 years | Demographic |
| 5 | v06 | Aged 65 - 84 years | Demographic |
| 6 | v07 | Aged 85 years and over | Demographic |
| 7 | v08 | Country of birth: Europe: United Kingdom | Ethnicity and Origins |
| 8 | v09 | Country of birth: Europe: EU countries | Ethnicity and Origins |
| 9 | v10 | Country of birth: Europe: Non-EU countries | Ethnicity and Origins |
| 10 | v11 | Country of birth: Africa | Ethnicity and Origins |
| 11 | v12 | Ethnic group: Bangladeshi | Ethnicity and Origins |
| 12 | v13 | Ethnic group: Chinese | Ethnicity and Origins |
| 13 | v14 | Ethnic group: Indian | Ethnicity and Origins |
| 14 | v15 | Ethnic group: Pakistani | Ethnicity and Origins |
| 15 | v16 | Ethnic group: Other Asian | Ethnicity and Origins |
| 16 | v17 | Ethnic group: Black | Ethnicity and Origins |
| 17 | v18 | Ethnic group: Mixed or Multiple ethnic groups | Ethnicity and Origins |
| 18 | v19 | Ethnic group: White | Ethnicity and Origins |
| 19 | v20 | Cannot speak English well or at all | Ethnicity and Origins |
| 20 | v21 | No religion | Ethnicity and Origins |
| 21 | v22 | Christian | Ethnicity and Origins |
| 22 | v23 | Other religion | Ethnicity and Origins |
| 23 | v24 | Never married and never registered a civil par... | Living Arrangements |
| 24 | v25 | Married or in a registered civil partnership | Living Arrangements |
| 25 | v26 | Separated or divorced | Living Arrangements |
| 26 | v27 | One-person household | Living Arrangements |
| 27 | v28 | Families with no children | Living Arrangements |
| 28 | v29 | Families with dependent children | Living Arrangements |
| 29 | v30 | All household members have the same ethnic group | Living Arrangements |
| 30 | v31 | Lives in a communal establishment | Usual Residence |
| 31 | v32 | Address 1 year ago is the same as the address ... | Usual Residence |
| 32 | v33 | Detached house or bungalow | Usual Residence |
| 33 | v34 | Semi-detached house or bungalow | Usual Residence |
| 34 | v35 | Terraced (including end-terrace) house or bung... | Usual Residence |
| 35 | v36 | Flat maisonette or apartment | Usual Residence |
| 36 | v37 | Ownership or shared ownership | Usual Residence |
| 37 | v38 | Social rented | Usual Residence |
| 38 | v39 | Private rented | Usual Residence |
| 39 | v40 | Occupancy rating of rooms: +1 or more | Usual Residence |
| 40 | v41 | Occupancy rating of rooms: -1 or less | Usual Residence |
| 41 | v42 | SIR | Other |
| 42 | v43 | Provides unpaid care | Other |
| 43 | v44 | 2 or more cars or vans in household | Other |
| 44 | v45 | Highest level of qualification: Level 1- 2 or ... | Other |
| 45 | v46 | Highest level of qualification: Level 3 qualif... | Other |
| 46 | v47 | Highest level of qualification: Level 4 qualif... | Other |
| 47 | v48 | Hours worked: Part-time | Employment |
| 48 | v49 | Hours worked: Full-time | Employment |
| 49 | v50 | NS-SeC: L15 Full-time students | Employment |
| 50 | v51 | SOC: 1. Managers directors and senior officials | Employment |
| 51 | v52 | SOC: 2. Professional occupations | Employment |
| 52 | v53 | SOC: 3. Associate professional and technical o... | Employment |
| 53 | v54 | SOC: 4. Administrative and secretarial occupat... | Employment |
| 54 | v55 | SOC: 5. Skilled trades occupations | Employment |
| 55 | v56 | SOC: 6. Caring leisure and other service occup... | Employment |
| 56 | v57 | SOC: 7. Sales and customer service occupations | Employment |
| 57 | v58 | SOC: 8. Process plant and machine operatives | Employment |
| 58 | v59 | SOC: 9. Elementary occupations | Employment |
| 59 | v60 | Economically active: Unemployed | Employment |
Examine the Data
We can plot the distribution of all the variables to get a sense of their distributions. Many of the variables are highly skewed, which is common for Census data. Skewed variables can be problematic for geodemographics because they cause distance metrics to be dominated by extreme values so effect the quality of clustering.
# Use pandas histogram plotting function with seaborn aesthetics
sns.set_style("whitegrid")
nrows = int(np.ceil(len(variable_df.columns) / 3))
variable_df_withnames = variable_df.copy()
variable_df_withnames.columns = var_lookup['Variable_Name'].values[:58]
variable_df_withnames.hist(bins=30, figsize=(7.5, nrows*1.5), edgecolor='black', layout=(nrows, 3))
plt.tight_layout()
plt.show()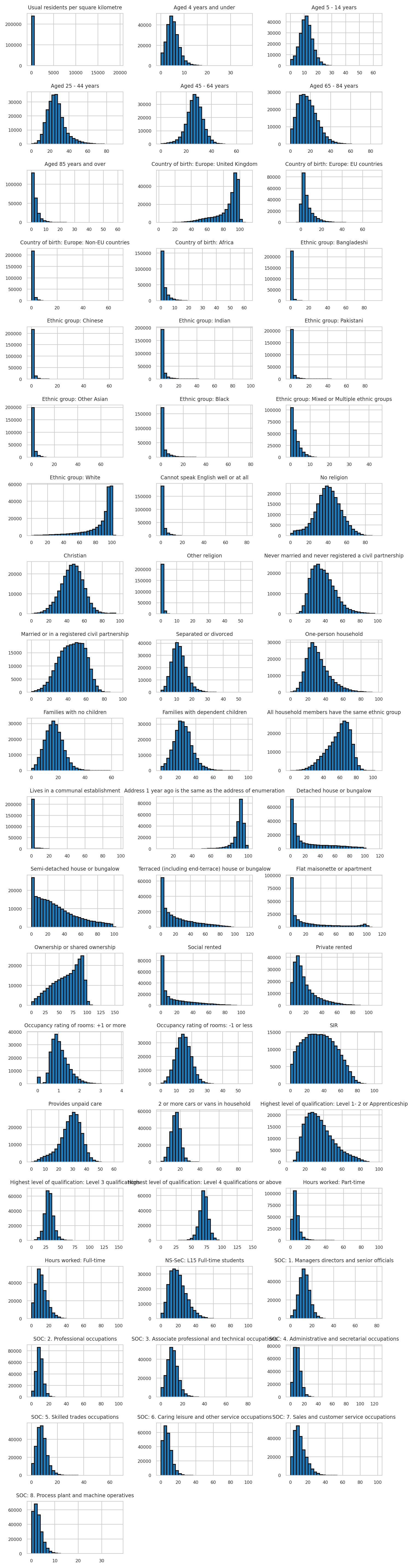
Spatial Data
We will also need the Output Area boundaries to map the results. The file used here is a GeoPackage containing the 2021 Output Area boundaries for the whole of the UK, clipped to the extent of England and Wales, Scotland, and Northern Ireland. The file has been created by joining the original files for each nation downloaded from the ONS Geoportal.
#---------
# Import spatial data
#---------
OA_Boundaries = gpd.read_file("input_data/OA_2021_22_Boundaries.gpkg").set_index('OA')
#---------
# Load Local Authority District (LAD) for region selection
#---------
LAD_Boundaries = gpd.read_file("input_data/Local_Authority_Districts_December_2022_UK_BGC_V2_5759908710055972638.gpkg")Selecting a Region
For this workshop, we will focus on a specific region of the UK to keep the analysis manageable.
Focusing on a specific region allows us to create a more detailed and relevant geodemographic classification for that area, capturing local nuances and characteristics that may be lost in a broader national classification. For example, a London specific OAC was developed as London has a drastically different demographic composition to the rest of the United Kingdom (Alex D. Singleton and Longley 2024).
Singleton, Alex D., and Paul A. Longley. 2024. “Classifying and Mapping Residential Structure Through the London Output Area Classification.” EPB: Urban Analytics and City Science 51 (5): 1153–64. https://doi.org/10.1177/23998083241242913.
By default we will use the Output Areas within the Liverpool City Region covering the city of liverpool and its surrounding areas. This region is prodominently urban and has a diverse population, making it an interesting case study for geodemographic classification. If running this notebook on your own machine, you can change the region of study from the selection below.
# region definitions (LAD22CD codes)
region_lads = {
"Greater Manchester": [
"E08000001","E08000002","E08000003","E08000004","E08000005",
"E08000006","E08000007","E08000008","E08000009","E08000010"
],
"Liverpool City Region": [
"E06000006","E08000011","E08000012","E08000013","E08000014",
"E08000015"
],
"Greater London": [
"E09000001","E09000002","E09000003","E09000004","E09000005",
"E09000006","E09000007","E09000008","E09000009","E09000010",
"E09000011","E09000012","E09000013","E09000014","E09000015",
"E09000016","E09000017","E09000018","E09000019","E09000020",
"E09000021","E09000022","E09000023","E09000024","E09000025",
"E09000026","E09000027","E09000028","E09000029","E09000030",
"E09000031","E09000032","E09000033"
],
"Scotland": [
"S12000005","S12000006","S12000008","S12000010","S12000011",
"S12000013","S12000014","S12000017","S12000018","S12000019",
"S12000020","S12000021","S12000023","S12000026","S12000027",
"S12000028","S12000029","S12000030","S12000033","S12000034",
"S12000035","S12000036","S12000038","S12000039","S12000040",
"S12000041","S12000042","S12000045","S12000047","S12000048",
"S12000049","S12000050"
],
"Northern Ireland": [
"N09000001","N09000002","N09000003","N09000004","N09000005",
"N09000006","N09000007","N09000008","N09000009","N09000010",
"N09000011"
],
"Wales": [
"W06000001","W06000002","W06000003","W06000004","W06000005",
"W06000006","W06000007","W06000008","W06000009","W06000010",
"W06000011","W06000012","W06000013","W06000014","W06000015",
"W06000016","W06000017","W06000018","W06000019","W06000020",
"W06000021","W06000022","W06000023","W06000024"
],
}Selecting the region of interest:
#Choose region from the list above by uncommenting the relevant line
lad_codes = region_lads["Liverpool City Region"]
# #or eg:
# lad_codes = region_lads["Greater Manchester"]
selected_lads = LAD_Boundaries[LAD_Boundaries["LAD22CD"].isin(lad_codes)]
# Spatial join to filter only intersecting OAs
oas_region = gpd.sjoin(OA_Boundaries, selected_lads[["geometry"]], predicate="intersects").drop(columns=["index_right"])
# drop duplicates (one which intersect with two LADs) using index
oas_region = oas_region[~oas_region.index.duplicated(keep='first')]
# --- Merge OA polygons with your variable data keeping only those with matching OAs in the region
oas_region_vars = oas_region.join(variable_df, how="inner")
# #keep only OAs in our region
variable_df_region=variable_df.loc[variable_df.index.isin(oas_region.index)]Map the Area
We will use Kepler.gl to visualise the Output Areas in our selected region. Kepler.gl is an open-source geospatial analysis tool that allows for interactive mapping and visualisation of large datasets.
#code to enable kepler in colab
from IPython.display import Javascript
display(Javascript('''
google.colab.widgets.installCustomManager('https://ssl.gstatic.com/colaboratory-static/widgets/colab-cdn-widget-manager/6a14374f468a145a/manager.min.js');
'''))
# --- Calculate region centroid for map centering ---
from shapely.ops import unary_union
region_geom = unary_union(
LAD_Boundaries.loc[LAD_Boundaries["LAD22CD"].isin(lad_codes), "geometry"]
)
region_centroid = region_geom.centroid
centroid_ll = gpd.GeoSeries([region_centroid], crs=LAD_Boundaries.crs).to_crs(epsg=4326).iloc[0]
centroid_lat, centroid_lon = centroid_ll.y, centroid_ll.x
# --- Quick Kepler map ---
area_map_ = KeplerGl(
height=600,
config={
"version": "v1",
"config": {
"mapState": {
'latitude': centroid_lat,
'longitude': centroid_lon,
"zoom": 9,
"pitch": 0,
"bearing": 0
}
}
}
)
# Add your layer
area_map_.add_data(data=oas_region_vars.reset_index(), name="OAs in Region")
# If you want to export to a standalone HTML:
area_map_.save_to_html(file_name="outputs/maps/region_oas_map.html")
# Show inside Jupyter
display(area_map_)Transform and Standardise Variables
Before applying clustering algorithms, it is important to transform and standardise the data to ensure that all variables contribute equally to the analysis.
The function below applies two transformations to a dataframe (applied column-wise):
- Inverse Hyperbolic Sine (IHS) transform
- Min–Max scaling to [0, 1]
Mathematical definitions
Inverse hyperbolic sine (IHS, a.k.a. arcsinh):
- Similar to a log transform but works with zero and negative values.
- Helps stabilise variance and make skewed distributions more normal-like.
\[ \mathrm{arcsinh}(x) = \ln\!\big(x + \sqrt{x^{2}+1}\big) \]
Properties: - For large (|x|):
\[
\mathrm{arcsinh}(x) \approx \ln(2|x|)
\] (behaves like log).
- Near (0):
\[ \mathrm{arcsinh}(x) \approx x \]
Min–Max scaling (applied per column after IHS):
\[ x' = \frac{x - \min(x)}{\max(x) - \min(x)} \]
- Rescales all values into the range ([0, 1]).
- Useful for comparing variables with different units/scales.
def transform_and_standardise_data(df):
"""Apply inverse hyperbolic sine transform, to account for non-normality
and then range standardise using min-max scaling to the dataframe."""
df = np.arcsinh(df)
denom = df.max() - df.min()
df = (df - df.min()) / denom.replace(0, 1) # prevent divide-by-zero
return df
# Transform the input data
transformed_variable_df = transform_and_standardise_data(variable_df_region)Variable Selection
In geodemographics, variable selection is crucial to turn large datasets (like the UK Census) with 100s of variables into meaningful clusters.
The nature of clustering means the high-dimensional space can be sparse and noisy, so reducing the number of variables helps improve cluster quality and interpretability.
Key points:
- Intention – variables depend on the purpose of the geodem (e.g. retail vs. health).
- Correlation – drop highly correlated variables to avoid redundancy.
- Variance – keep variables that vary across places (so they can distinguish areas).
- Expert choice – ensure selected variables are socially meaningful.
Here we are using a broad, pre-selected dataset which was used for the UK OAC 2021 classification. So we expect the variables to be broadly suitable for our region of interest.
New methods include:
- Automated variable selection (Liu, Singleton, and Arribas‐Bel 2019) – uses statistical procedure to determine a subset of variables which produce the best clustering results.
- Autoencoders – Use neural networks to compress all variables into a smaller set of features, while preserving the most important patterns.
Liu, Yunzhe, Alex Singleton, and Daniel Arribas‐Bel. 2019. “A Principal Component Analysis (PCA)‐based Framework for Automated Variable Selection in Geodemographic Classification.” Geo‐spatial Information Science 22 (4): 251–64. https://doi.org/10.1080/10095020.2019.1621549.
Correlation & Variance Analysis
transformed_variable_df_withnames = transformed_variable_df.copy()
transformed_variable_df_withnames.columns = [var_lookup.set_index("No.")["Variable_Name"].to_dict().get(col, col) for col in transformed_variable_df.columns]
# --- Correlation Check ---
corr_matrix = transformed_variable_df_withnames.corr()
# --- Interactive heatmap with Plotly ---
fig = px.imshow(
corr_matrix.values,
color_continuous_scale="RdBu_r",
zmin=-1, zmax=1,
title="Correlation Heatmap",
x=corr_matrix.columns,
y=corr_matrix.columns,
)
# Add hover names for tooltips
fig.update_traces(
hovertemplate="<b>%{x}</b> vs <b>%{y}</b><br>Correlation: %{z:.3f}<extra></extra>",
)
# Hide x/y tick labels but keep tooltips
fig.update_xaxes(showticklabels=False)
fig.update_yaxes(showticklabels=False)
fig.update_layout(
width=700,
height=700,
coloraxis_colorbar=dict(len=0.8, thickness=15),
margin=dict(l=40, r=40, t=60, b=40)
)
fig.show()
# --- Find highly correlated pairs (print each pair twice) ---
cols = corr_matrix.columns
# consider only upper triangle to get unique unordered pairs (i < j)
upper_mask = np.triu(np.ones(corr_matrix.shape, dtype=bool), k=1)
# build mask for correlations above 0.95 (and exclude perfect 1.0)
corr_threshold = 0.95
corr_vals = corr_matrix.values
# consider only upper triangle unique pairs (i < j) and print each once once
mask = ((corr_vals > corr_threshold) & upper_mask)
pairs = np.column_stack(np.where(mask))
for i, j in pairs:
col_i, col_j = cols[i], cols[j]
val = corr_matrix.iat[i, j]
print(f"High correlation between {col_i} and {col_j}: {val:.3f}")
# --- Variance Check ---
variances = transformed_variable_df_withnames.var()
#plot the variances
plt.figure(figsize=(8, 5))
variances.sort_values().plot(kind='bar')
plt.ylabel('Variance')
plt.title('Variance of Each Variable')
plt.show()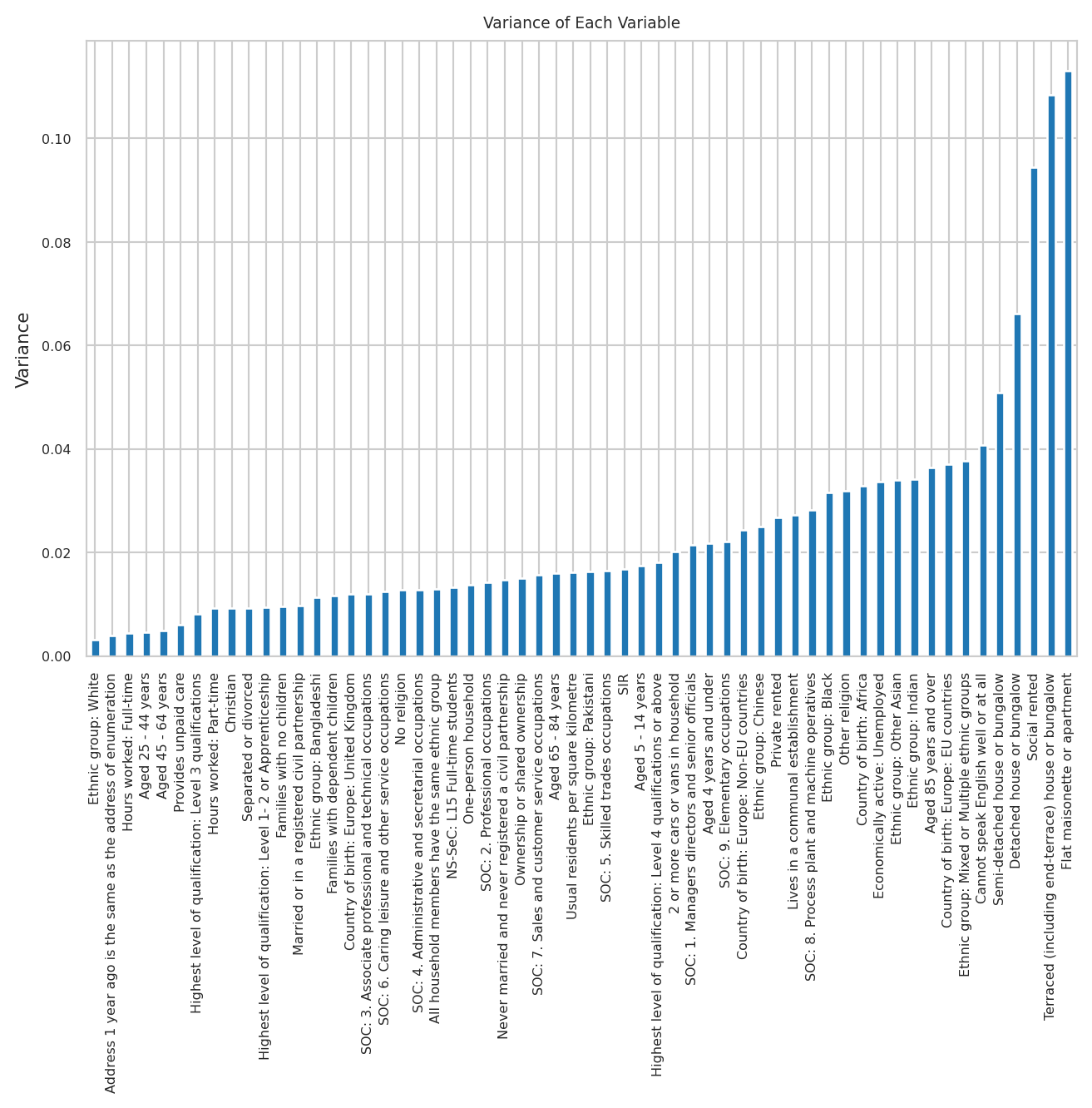
Selecting Variables
If we want to remove any variables we can do so here. This could be based on the analysis above or to tailor the classification to a specific purpose.
drop_vars = []# No variables to drop, use variable selection as is.
# for northern ireland bangladeshi ethnicity variable should be removed as variation is zero (no counts)
# drop_vars = ['v12']
cleaned_variable_df = transformed_variable_df.drop(columns=drop_vars)
# We could also focus on a specific theme, for example education and work
# related variables only:
# ed_work_vars = ['v45','v46','v47','v48','v49','v50','v51','v52','v53',
# 'v54','v55','v56', 'v57','v58','v59','v60']
# cleaned_variable_df = transformed_variable_df[ed_work_vars]K-Means Clustering
K-means clustering is the most commonly used clustering algorithm for geodemographic classification. It partitions a dataset into k groups (clusters), where each observation belongs to the cluster with the nearest mean (centroid). The algorithm iteratively updates cluster assignments and centroids until convergence.
How it works (simplified):
- Choose the number of clusters (k).
- Initialise k centroids (usually at random points in the data space).
- Assign each data point to the nearest centroid.
- Update centroids as the mean of the points in each cluster.
- Repeat steps 3–4 until assignments no longer change (or improvement is below a threshold).
Strengths:
- Simple and computationally efficient.
- Works well when clusters are roughly spherical and similar in size.
Limitations:
- Requires specifying k in advance.
- Sensitive to outliers and scaling of features.
- Assumes clusters are convex1 and isotropic2; k‑means effectively assumes clusters are roughly spherical with similar variance in every direction, which may not hold in real data.
- Dimensionality: K-means can struggle in very high-dimensional spaces due to the “curse of dimensionality”
1 A set is convex if, for any two points in the set, the straight line between them lies entirely within the set.
2 Having uniform properties in all directions
More details and examples can be found here: Scikit-learn: K-Means
Choosing the Number of Clusters (k) - Clustergrams
When using k-means clustering, one of the key decisions is selecting the optimal number of clusters (k). This choice can significantly impact the quality and interpretability of the resulting geodemographic classification. Key considerations when choosing k:
- Each cluster be as homogeneous as possible.
- Each cluster should be as distinct from the others as possible.
- The clusters should be as evenly sized as possible.
Clustergrams (Fleischmann 2023) are visualisation technique that shows how cluster assignments change as you increase the number of clusters (k). This helps you to understand the structure in very high-dimensional space in the following ways:
Fleischmann, Martin. 2023. “Clustergram: Visualization and Diagnostics for Cluster Analysis.” Journal of Open Source Software 8 (89): 5240. https://doi.org/10.21105/joss.05240.
- Cluster separation: Helps you to determine the right number of clusters by visualising how cleanly clusters separate
- Cluster stability: Shows which clusters persist across different k values (stable long lines) vs. those which are artifacts of over-clustering (short, erratic lines)
- Split patterns: Reveals the natural hierarchy in the data by showing how clusters subdivide
Further guidance on interpreting clustergrams and choosing the number of clusters can be found here: Clustergram
# Since k-means is sensitive to initialization, `n_init` determines the number of
# times the algorithm runs with different centroid seeds. The final result is the
# best outcome based on inertia/WCSS (within-cluster sum of squares).
n_init = 100 # Use a low value for quick testing, increase (~100) for final results
cgram = Clustergram(range(1, 10), n_init=n_init, random_state=random_seed,verbose=False) # Initialize clustergram model
cgram.fit(cleaned_variable_df) # Fit model to data
cgram.plot() # Generate plot
plt.savefig("outputs/plots/supergroup_clustergram.png") # Save figure
plt.show() # Display plot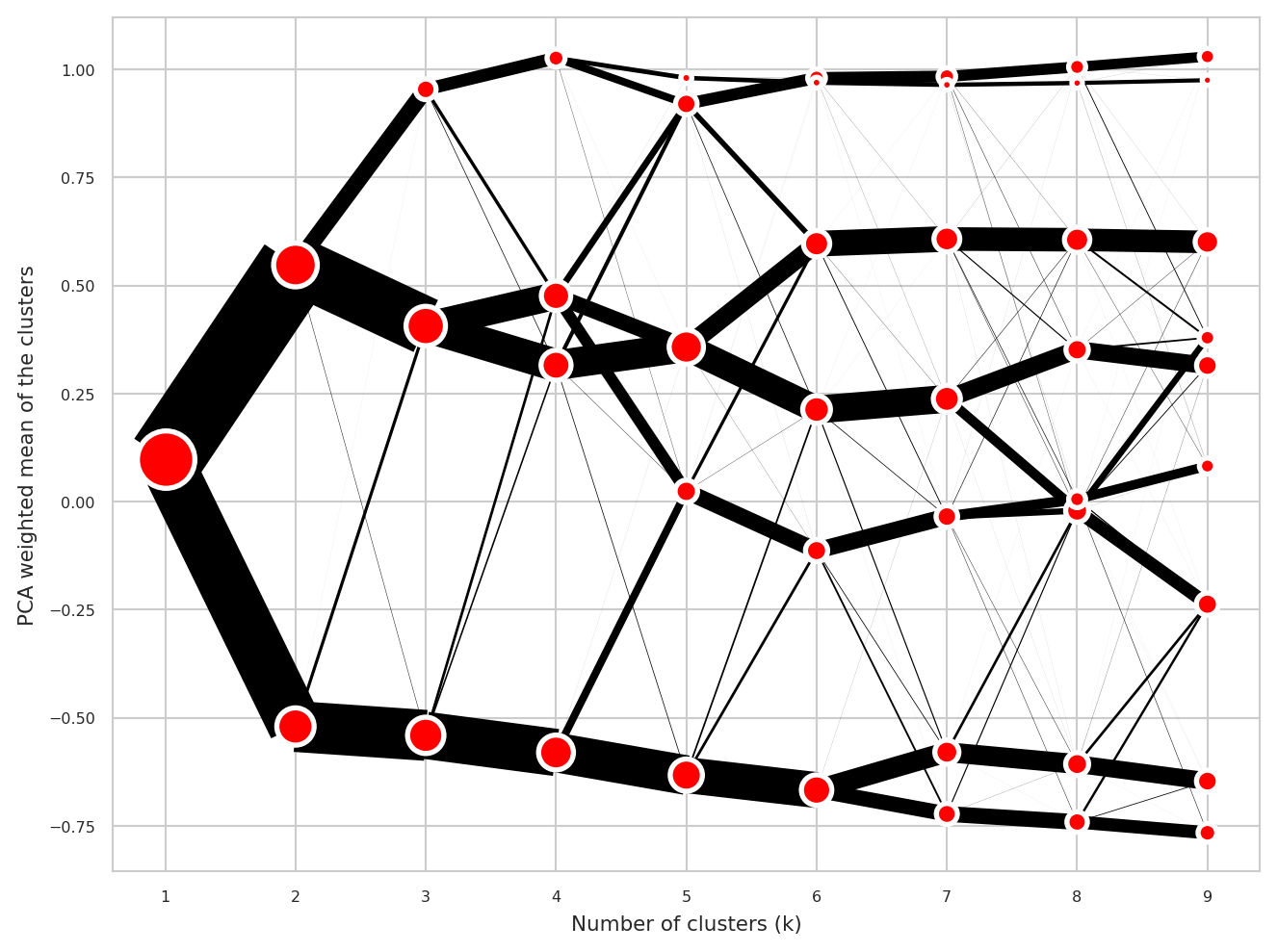
Choose the number of clusters (k) based on the clustergram above.
# Define the number of clusters (K). Choose K based on the clustergram plot.
num_clusters = 5Apply K-Means Clustering
# num_clusters (int): The number of clusters (K) to create.
# n_init (int): Number of times the K-means algorithm runs with different initial
# centroid seeds. The best result based on inertia/WCSS is chosen.
# A higher value (e.g., ~1000) is recommended for final results,
# but a lower value can be used for testing.
n_init = 1000 # Use a low value for quick testing, increase (~100) for final results
output_filepath = "outputs/supergroups_clusteroutput.csv"
# Initialize the K-means model
kmeans_model = KMeans(n_clusters=num_clusters,init="random", random_state=random_seed, n_init=n_init)
# Fit the model and assign clusters to a new dataframe which is a copy of the input data
supergrouped_variable_df = cleaned_variable_df.copy()
supergrouped_variable_df['cluster'] = kmeans_model.fit_predict(cleaned_variable_df)
# Ensure output directory exists
os.makedirs(os.path.dirname(output_filepath), exist_ok=True)
# Save the cluster assignments to a CSV file
supergrouped_variable_df[['cluster']].to_csv(output_filepath)
# Map numeric labels to letters
label_map = {i: chr(65 + i) for i in range(num_clusters)} # 0->A, 1->B, etc.
supergrouped_variable_df['cluster'] = supergrouped_variable_df['cluster'].map(label_map)
#view the output
supergrouped_variable_df["cluster"]OA
E00031533 E
E00031534 E
E00031558 E
E00031561 A
E00031563 E
..
E00188896 B
E00188900 E
E00188911 A
E00188915 E
E00188927 C
Name: cluster, Length: 5258, dtype: objectMapping the Clusters
We can visualise the clusters on a map to see their spatial distribution.
UMAP Visualisation
We can use UMAP (Uniform Manifold Approximation and Projection) (McInnes, Healy, and Melville 2020) to visualise the high-dimensional Census data in 2D. UMAP is a dimensionality reduction technique that preserves both local and global structure in the data, making it well-suited for visualising complex datasets like Census data.
McInnes, Leland, John Healy, and James Melville. 2020. “UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction.” https://arxiv.org/abs/1802.03426.
# Features = all columns except the cluster label
features = [c for c in supergrouped_variable_df.columns if c != 'cluster']
# Extract features and labels (transformed)
X = supergrouped_variable_df[features].values
labels = supergrouped_variable_df['cluster'].values
# Fit UMAP
# Apply UMAP to reduce 64 dimensions to 2D
reducer = umap.UMAP(
n_neighbors=30, # Numbers of neighbours
min_dist=0.0, # Allow points to be closer together
n_components=2, # Reduce to 2D for visualsation
random_state=508, # For reproducible results
metric='cosine', # Cosine similarity
init='random', # Use random initialisation
n_epochs=500, # More epochs for better convergence
spread=1.0, # Controls how tightly points are packed
verbose=False # Show progress
)
embedding = reducer.fit_transform(X)
umap_results = pd.DataFrame({
'UMAP1': embedding[:, 0],
'UMAP2': embedding[:, 1],
'Cluster': labels
})
# Save the UMAP results
umap_results.to_parquet('outputs/umap_results.parquet', index=False)/home/ogoodwin/projects/GeoDem_CartoWorkshop2025/.venv/lib/python3.12/site-packages/umap/umap_.py:1952: UserWarning:
n_jobs value 1 overridden to 1 by setting random_state. Use no seed for parallelism.
# Define colours for each cluster - same as earlier map
colours = {
"A": '#8dd3c7',
"B": '#ffffb3',
"C": '#bebada',
"D": '#fb8072',
"E": '#fdb462',
"F": "#235477",
"G": '#fccde5',
"H": '#d9d9d9',
"I": '#bc80bd',
"J": '#ccebc5'
}
# Create interactive UMAP scatter plot
fig_interactive = px.scatter(
umap_results,
x='UMAP1',
y='UMAP2',
color='Cluster',
category_orders={"Cluster": sorted(umap_results["Cluster"].unique())}, #
color_discrete_map=colours,
)
# Style tweaks
fig_interactive.update_traces(marker=dict(size=3, opacity=0.7))
fig_interactive.update_layout(
title="UMAP Projection of Clusters",
xaxis_title="UMAP 1",
yaxis_title="UMAP 2",
legend_title="Cluster"
)
#save to html
fig_interactive.write_html("outputs/umap_interactive.html")
# fig_interactive.update_layout(width=800, height=600)
fig_interactive.show(config={"responsive": False})The UMAP projection shows there is reasonable separation between the clusters, indicating that the k-means clustering has identified distinct groups in the data. In particular the small cluster in the bottom left which represents the city centre in our case study of Liverpool, is well-defined and separated from other clusters.
There are indications of further structure within clusters, which could be explored further using hierarchical clustering to subdivide clusters into subclusters. More on that in a bit.. for now lets dig into the clusters that we’ve got.
Cluster Profiling, Naming, and Describing using Language Models
We can explore the characteristics of each cluster using summary statistics and index scores. This helps us understand each cluster.
Cluster Statistics
#Lot at the characteristics of each cluster
# Read in the data
pop_size = pd.read_csv("input_data/oa_pop_data.csv")
pop_size = pop_size.set_index('OA')
#rename column to "population"
pop_size = pop_size.rename(columns={'uk001001': 'population'})
pop_size = pop_size['population']
#basic statistics of each cluster, number (perc of OAs) in each cluster and population
#number of OAs in each cluster
cluster_counts = supergrouped_variable_df['cluster'].value_counts().sort_index()
#percentage of OAs in each cluster
cluster_perc = (cluster_counts / cluster_counts.sum() * 100).round(2)
#join pop_size to supergrouped_variable_df on index
supergrouped_variable_df_withpop = supergrouped_variable_df.join(pop_size, how='left')
#pop in each cluster
cluster_pop = supergrouped_variable_df_withpop.groupby('cluster')['population'].sum()
#percentage of pop in each cluster
cluster_pop_perc = (cluster_pop / cluster_pop.sum() * 100).round(2)
#combine into a dataframe
cluster_summary = pd.DataFrame({
'Number of OAs': cluster_counts,
'Percentage of OAs': cluster_perc,
'Population': cluster_pop,
'Percentage of Population': cluster_pop_perc
})
cluster_summary| Number of OAs | Percentage of OAs | Population | Percentage of Population | |
|---|---|---|---|---|
| cluster | ||||
| A | 804 | 15.29 | 226794 | 14.40 |
| B | 737 | 14.02 | 225164 | 14.30 |
| C | 1875 | 35.66 | 555477 | 35.28 |
| D | 192 | 3.65 | 61126 | 3.88 |
| E | 1650 | 31.38 | 505879 | 32.13 |
Cluster Profiling
Index scores are a way to summarise how a particular variable behaves within a cluster compared to the overall average. They help identify which characteristics are over- or under-represented in each cluster.
Index scores are calculated as follows:
\[ \text{Index Score} = \left( \frac{\text{Mean of Variable in Cluster}}{\text{Overall Mean of Variable}} \right) \times 100 \]
Where:
- Mean of Variable in Cluster: the average value of the variable for all areas within the specific cluster.
- Overall Mean of Variable: the average value of the variable across all areas in the dataset.
Here we will look only at variables used in the clustering. It can also be useful to look at variables not used in the clustering or from other data sources to help understand the clusters.
# map encoding -> human name
encoding_to_name = dict(zip(var_lookup["No."], var_lookup["Variable_Name"]))
features = [c for c in supergrouped_variable_df.columns if c != 'cluster']
#dont average the cluster column
cluster_means = supergrouped_variable_df.groupby('cluster').mean()
global_means = supergrouped_variable_df[features].mean()
# --- Calculate percentage difference ---
pct_diff = (cluster_means / global_means) * 100
#drop columns with nan
pct_diff = pct_diff.dropna(axis=1, how='any')
# Transpose for easier plotting (rows: encodings, columns: clusters)
pct_display_df = pct_diff.T
# build human names for hover
human_names = pct_display_df.index.map(lambda e: encoding_to_name.get(e)).values
customdata_pct = np.tile(human_names.reshape(-1, 1), (1, pct_display_df.shape[1]))
# --- Heatmap (percentage difference) ---
fig_pct = px.imshow(
pct_display_df,
color_continuous_scale="RdYlGn",
origin="lower",
aspect="auto",
labels=dict(x="Cluster", y="Feature (encoding)", color="% of global mean"),
zmin=0,
zmax=200
)
# attach customdata and set hover
fig_pct.data[0].customdata = customdata_pct
fig_pct.update_traces(
hovertemplate="Cluster: %{x}<br>Encoding: %{y}<br>Name: %{customdata}<br>% of Global Mean: %{z:.1f}%<extra></extra>",
zmid=100 # centre colours on 100%
)
fig_pct.update_layout(
title="Cluster Profiles (% of Global Mean)",
xaxis_title="Cluster",
yaxis_title="Feature (encoding)",
height=800
)
fig_pct.show()LLM Cluster Naming (and description)
To create a useful geodemographic classification, we need to assign meaningful names and descriptions to each cluster. This helps in interpreting the clusters and communicating their characteristics effectively.
Traditionally, this is done manually by examining the statistical profiles of each cluster and using domain knowledge to assign names. It is a time consuming process. However, we can leverage Large Language Models (LLMs) to assist in this process.
We have demonstrated that LLMs can be used to generate initial name and description suggestions based on the statistical profiles of each cluster (Alex D. Singleton and Spielman 2024). We can use LLMs to generate initial name and description suggestions based on the statistical profiles of each cluster. Here only the variables used in the clustering are included. It can also be useful to include other variables or external data to provide more context for the LLM.
Singleton, Alex D., and Seth Spielman. 2024. “Segmentation Using Large Language Models: A New Typology of American Neighborhoods.” EPJ Data Science 13 (34). https://doi.org/10.1140/epjds/s13688-024-00466-1.
Using the OpenAI API
Below I use the OpenAI API, if you have an API key insert it in an .env file3 as OPENAI_API_KEY=“sk….sA”
3 .env files are files that contain environment variables, they can be created as a plain text file (named .env) in the root directory. These files often contain private information so should not be commited to git
If you do have an API key skip the next cell and go to the cell where we will use a browser prompt to get the cluster names and descriptions.
from dotenv import load_dotenv
load_dotenv() # this loads variables from .env into environment
#get your OpenAI API key from environment variable
openai_api_key = os.getenv("OPENAI_API_KEY")
if not openai_api_key:
raise ValueError("Please set the OPENAI_API_KEY environment variable.")
client = openai.OpenAI(api_key=openai_api_key)
# -------------------------
# JSON Schema for output
# -------------------------
cluster_schema = {
"type": "object",
"properties": {
"name": {"type": "string"},
"description": {"type": "string"},
},
"required": ["name", "description"],
"additionalProperties": False,
}
system_prompt = """You are a geodemographic analyst.
Your task is to produce commercial-style geodemographic cluster pen portraits
and cluster names."""
user_prompt = """
A geodemographics company is trying to explain the characteristics
of several neighborhoods to a new customer. They present data comparing each
neighborhood to the region average. A score of 100 means the neighborhood
is equivalent to the regional average, 150 means one and a half times,
200 means twice, 50 means half, and 300 means three times the regional average.
Write a pen portrait for the neighborhood based on the data provided.
The description of each neighborhood should focus on characteristics with
scores above 120 or below 80. Write in the third person, no more than 500 words.
Do not mention the specific scores.
Instead, describe patterns relative to the regional average (above/below).
In the style of a commercial geodemographic classification,
create a cluster name that summarises the pen portrait.
The name should capture as many different characteristics as possible
and be no more than 3 words.
"""
# -------------------------
# Loop through clusters
# -------------------------
cluster_summaries = {}
for cluster in pct_diff.index:
cluster_pct = pct_diff.loc[cluster]
cluster_data = {
"cluster": cluster,
"data": {
encoding_to_name.get(feature): round(value, 1)
for feature, value in cluster_pct.items()
},
}
response = client.responses.create(
model="gpt-5-mini",
input=[
{"role": "system", "content": system_prompt.strip()},
{"role": "user", "content": user_prompt.strip()},
{"role": "user", "content": json.dumps(cluster_data)},
],
text={
"format": {
"type": "json_schema",
"name": "cluster_summary",
"schema": cluster_schema,
"strict": True,
}
},
)
cluster_summary = json.loads(response.output_text)
# store under your cluster ID
cluster_summaries[cluster] = cluster_summary
cluster_summariesPrompt for Browser Based LLM
The follow code cell generates a prompt for to be used in an LLM of your choice. Try it in your browser based LLM of choice (e.g. chatGPT, Claude, Gemini, etc)
The prompt should insure that the LLM produses the output in the correct format but this cannot be guaranteed.
#print the prompt to copy and paste into a LLM to generate cluster descriptions
prompt_intial = """
A geodemographics company is trying to explain the characteristics of several neighbourhoods to a new customer.
They present data comparing each neighbourhood to the region average.
A score of 100 means the neighbourhood is equivalent to the national average,
a score of 150 means the neighbourhood is one and a half times the national average,
a score of 200 means the neighbourhood is twice the national average,
a score of 50 means the neighbourhood is half of the region average,
a score of 300 means the neighbourhood is three times the region average.
Each neighbourhood has the following characteristics, described in #DATA# below.
Data are presented for each characteristic followed by a colon, and then a score.
The description of each neighbourhood should focus on characteristics that have scores which are greater than 120 or less than 80.
Write a separate description for each cluster (Cluster A, Cluster B, Cluster C, Cluster D, etc.
Each description should be written in the third person, in no more than 500 words. Do not mention the specific scores from the #DATA#.
Instead, use descriptive words to illustrate rates that are above or below the regional average.
Make comparisons to the regional average, do not talk in absolute terms.
"""
prompt_data =""
# print the index scores for each cluster in this format:
for cluster in pct_diff.index:
prompt_data += f"\n#DATA# cluster_key: {cluster}\n"
cluster_pct = pct_diff.loc[cluster]
for feature, value in cluster_pct.items():
feature_name = encoding_to_name.get(feature)
prompt_data += f"{feature_name}: {value:.1f}\n"
prompt_struc = """
In the style of a commercial geodemographic classification; create a cluster name
that would summarise the created geodemographic pen portraits. The names should capture as many
different characteristics contained within the description as possible.
The cluster name should be no more than 3 words.
Return your response in JSON format with the structure:
{"cluster_key_1": {"name": "", "description": ""},
"cluster_key_2": {"name": "", "description": ""},...}"""
full_prompt = prompt_intial + prompt_data + prompt_struc
print(full_prompt)
A geodemographics company is trying to explain the characteristics of several neighbourhoods to a new customer.
They present data comparing each neighbourhood to the region average.
A score of 100 means the neighbourhood is equivalent to the national average,
a score of 150 means the neighbourhood is one and a half times the national average,
a score of 200 means the neighbourhood is twice the national average,
a score of 50 means the neighbourhood is half of the region average,
a score of 300 means the neighbourhood is three times the region average.
Each neighbourhood has the following characteristics, described in #DATA# below.
Data are presented for each characteristic followed by a colon, and then a score.
The description of each neighbourhood should focus on characteristics that have scores which are greater than 120 or less than 80.
Write a separate description for each cluster (Cluster A, Cluster B, Cluster C, Cluster D, etc.
Each description should be written in the third person, in no more than 500 words. Do not mention the specific scores from the #DATA#.
Instead, use descriptive words to illustrate rates that are above or below the regional average.
Make comparisons to the regional average, do not talk in absolute terms.
#DATA# cluster_key: A
Usual residents per square kilometre: 94.8
Aged 4 years and under: 87.1
Aged 5 - 14 years: 91.7
Aged 25 - 44 years: 96.2
Aged 45 - 64 years: 101.9
Aged 65 - 84 years: 110.4
Aged 85 years and over: 139.5
Country of birth: Europe: United Kingdom: 102.4
Country of birth: Europe: EU countries: 96.7
Country of birth: Europe: Non-EU countries: 98.1
Country of birth: Africa: 84.3
Ethnic group: Bangladeshi: 99.4
Ethnic group: Chinese: 104.1
Ethnic group: Indian: 111.3
Ethnic group: Pakistani: 83.1
Ethnic group: Other Asian: 89.4
Ethnic group: Black: 67.3
Ethnic group: Mixed or Multiple ethnic groups: 98.0
Ethnic group: White: 101.1
Cannot speak English well or at all: 65.9
No religion: 99.0
Christian: 101.8
Other religion: 103.2
Never married and never registered a civil partnership: 92.0
Married or in a registered civil partnership: 102.5
Separated or divorced: 106.6
One-person household: 110.9
Families with no children: 101.2
Families with dependent children: 91.7
All household members have the same ethnic group: 92.3
Lives in a communal establishment: 204.1
Address 1 year ago is the same as the address of enumeration: 100.5
Detached house or bungalow: 113.9
Semi-detached house or bungalow: 96.8
Terraced (including end-terrace) house or bungalow: 85.8
Flat maisonette or apartment: 185.1
Ownership or shared ownership: 103.6
Social rented: 92.7
Private rented: 107.7
SIR: 94.5
Provides unpaid care: 100.0
2 or more cars or vans in household: 102.9
Highest level of qualification: Level 1- 2 or Apprenticeship: 97.2
Highest level of qualification: Level 3 qualifications: 94.6
Highest level of qualification: Level 4 qualifications or above: 111.2
Hours worked: Part-time: 95.7
Hours worked: Full-time: 101.9
NS-SeC: L15 Full-time students: 87.5
SOC: 1. Managers directors and senior officials: 112.0
SOC: 2. Professional occupations: 109.4
SOC: 3. Associate professional and technical occupations: 104.1
SOC: 4. Administrative and secretarial occupations: 101.1
SOC: 5. Skilled trades occupations: 96.4
SOC: 6. Caring leisure and other service occupations: 94.5
SOC: 7. Sales and customer service occupations: 90.8
SOC: 8. Process plant and machine operatives: 88.1
SOC: 9. Elementary occupations: 88.9
Economically active: Unemployed: 85.5
#DATA# cluster_key: B
Usual residents per square kilometre: 112.2
Aged 4 years and under: 111.4
Aged 5 - 14 years: 103.2
Aged 25 - 44 years: 105.4
Aged 45 - 64 years: 96.4
Aged 65 - 84 years: 88.2
Aged 85 years and over: 66.7
Country of birth: Europe: United Kingdom: 83.6
Country of birth: Europe: EU countries: 163.6
Country of birth: Europe: Non-EU countries: 194.6
Country of birth: Africa: 244.0
Ethnic group: Bangladeshi: 261.6
Ethnic group: Chinese: 177.7
Ethnic group: Indian: 153.1
Ethnic group: Pakistani: 288.6
Ethnic group: Other Asian: 232.3
Ethnic group: Black: 283.7
Ethnic group: Mixed or Multiple ethnic groups: 150.7
Ethnic group: White: 92.9
Cannot speak English well or at all: 285.7
No religion: 100.0
Christian: 93.3
Other religion: 124.9
Never married and never registered a civil partnership: 116.0
Married or in a registered civil partnership: 90.5
Separated or divorced: 103.5
One-person household: 109.5
Families with no children: 89.5
Families with dependent children: 100.9
All household members have the same ethnic group: 90.1
Lives in a communal establishment: 90.3
Address 1 year ago is the same as the address of enumeration: 97.6
Detached house or bungalow: 79.1
Semi-detached house or bungalow: 83.2
Terraced (including end-terrace) house or bungalow: 138.5
Flat maisonette or apartment: 150.1
Ownership or shared ownership: 84.5
Social rented: 146.0
Private rented: 119.0
SIR: 119.1
Provides unpaid care: 95.3
2 or more cars or vans in household: 78.3
Highest level of qualification: Level 1- 2 or Apprenticeship: 97.3
Highest level of qualification: Level 3 qualifications: 94.5
Highest level of qualification: Level 4 qualifications or above: 92.6
Hours worked: Part-time: 108.3
Hours worked: Full-time: 95.8
NS-SeC: L15 Full-time students: 115.7
SOC: 1. Managers directors and senior officials: 84.5
SOC: 2. Professional occupations: 91.4
SOC: 3. Associate professional and technical occupations: 90.6
SOC: 4. Administrative and secretarial occupations: 92.0
SOC: 5. Skilled trades occupations: 97.0
SOC: 6. Caring leisure and other service occupations: 108.0
SOC: 7. Sales and customer service occupations: 107.9
SOC: 8. Process plant and machine operatives: 109.4
SOC: 9. Elementary occupations: 119.4
Economically active: Unemployed: 134.5
#DATA# cluster_key: C
Usual residents per square kilometre: 104.5
Aged 4 years and under: 109.8
Aged 5 - 14 years: 107.5
Aged 25 - 44 years: 102.2
Aged 45 - 64 years: 100.4
Aged 65 - 84 years: 96.8
Aged 85 years and over: 87.1
Country of birth: Europe: United Kingdom: 103.5
Country of birth: Europe: EU countries: 96.0
Country of birth: Europe: Non-EU countries: 74.9
Country of birth: Africa: 71.1
Ethnic group: Bangladeshi: 63.9
Ethnic group: Chinese: 64.3
Ethnic group: Indian: 59.4
Ethnic group: Pakistani: 44.6
Ethnic group: Other Asian: 79.0
Ethnic group: Black: 75.7
Ethnic group: Mixed or Multiple ethnic groups: 91.9
Ethnic group: White: 101.5
Cannot speak English well or at all: 88.4
No religion: 105.5
Christian: 99.1
Other religion: 103.6
Never married and never registered a civil partnership: 108.4
Married or in a registered civil partnership: 96.5
Separated or divorced: 105.7
One-person household: 101.5
Families with no children: 95.7
Families with dependent children: 105.1
All household members have the same ethnic group: 102.0
Lives in a communal establishment: 54.0
Address 1 year ago is the same as the address of enumeration: 101.4
Detached house or bungalow: 76.0
Semi-detached house or bungalow: 100.7
Terraced (including end-terrace) house or bungalow: 142.0
Flat maisonette or apartment: 90.9
Ownership or shared ownership: 97.1
Social rented: 136.9
Private rented: 102.8
SIR: 116.5
Provides unpaid care: 101.9
2 or more cars or vans in household: 94.8
Highest level of qualification: Level 1- 2 or Apprenticeship: 105.4
Highest level of qualification: Level 3 qualifications: 99.3
Highest level of qualification: Level 4 qualifications or above: 83.9
Hours worked: Part-time: 102.8
Hours worked: Full-time: 99.2
NS-SeC: L15 Full-time students: 99.5
SOC: 1. Managers directors and senior officials: 89.6
SOC: 2. Professional occupations: 89.1
SOC: 3. Associate professional and technical occupations: 95.1
SOC: 4. Administrative and secretarial occupations: 98.8
SOC: 5. Skilled trades occupations: 104.8
SOC: 6. Caring leisure and other service occupations: 109.1
SOC: 7. Sales and customer service occupations: 107.8
SOC: 8. Process plant and machine operatives: 113.4
SOC: 9. Elementary occupations: 112.0
Economically active: Unemployed: 116.2
#DATA# cluster_key: D
Usual residents per square kilometre: 114.2
Aged 4 years and under: 59.2
Aged 5 - 14 years: 48.6
Aged 25 - 44 years: 109.3
Aged 45 - 64 years: 77.7
Aged 65 - 84 years: 59.3
Aged 85 years and over: 27.4
Country of birth: Europe: United Kingdom: 72.6
Country of birth: Europe: EU countries: 176.4
Country of birth: Europe: Non-EU countries: 326.4
Country of birth: Africa: 240.6
Ethnic group: Bangladeshi: 249.1
Ethnic group: Chinese: 294.9
Ethnic group: Indian: 306.9
Ethnic group: Pakistani: 327.4
Ethnic group: Other Asian: 220.5
Ethnic group: Black: 259.9
Ethnic group: Mixed or Multiple ethnic groups: 185.4
Ethnic group: White: 91.5
Cannot speak English well or at all: 203.5
No religion: 120.6
Christian: 70.6
Other religion: 213.9
Never married and never registered a civil partnership: 132.4
Married or in a registered civil partnership: 68.7
Separated or divorced: 78.5
One-person household: 120.9
Families with no children: 106.8
Families with dependent children: 63.9
All household members have the same ethnic group: 68.0
Lives in a communal establishment: 527.8
Address 1 year ago is the same as the address of enumeration: 78.0
Detached house or bungalow: 34.8
Semi-detached house or bungalow: 33.1
Terraced (including end-terrace) house or bungalow: 51.1
Flat maisonette or apartment: 233.3
Ownership or shared ownership: 72.1
Social rented: 111.1
Private rented: 140.7
SIR: 84.4
Provides unpaid care: 76.3
2 or more cars or vans in household: 68.8
Highest level of qualification: Level 1- 2 or Apprenticeship: 63.2
Highest level of qualification: Level 3 qualifications: 117.3
Highest level of qualification: Level 4 qualifications or above: 126.3
Hours worked: Part-time: 95.8
Hours worked: Full-time: 96.6
NS-SeC: L15 Full-time students: 147.5
SOC: 1. Managers directors and senior officials: 91.0
SOC: 2. Professional occupations: 115.7
SOC: 3. Associate professional and technical occupations: 107.8
SOC: 4. Administrative and secretarial occupations: 91.6
SOC: 5. Skilled trades occupations: 72.5
SOC: 6. Caring leisure and other service occupations: 83.4
SOC: 7. Sales and customer service occupations: 102.4
SOC: 8. Process plant and machine operatives: 63.9
SOC: 9. Elementary occupations: 102.7
Economically active: Unemployed: 110.1
#DATA# cluster_key: E
Usual residents per square kilometre: 90.3
Aged 4 years and under: 94.8
Aged 5 - 14 years: 100.0
Aged 25 - 44 years: 95.8
Aged 45 - 64 years: 102.8
Aged 65 - 84 years: 108.6
Aged 85 years and over: 118.8
Country of birth: Europe: United Kingdom: 105.3
Country of birth: Europe: EU countries: 68.9
Country of birth: Europe: Non-EU countries: 60.8
Country of birth: Africa: 59.8
Ethnic group: Bangladeshi: 51.7
Ethnic group: Chinese: 81.1
Ethnic group: Indian: 92.8
Ethnic group: Pakistani: 60.5
Ethnic group: Other Asian: 55.9
Ethnic group: Black: 42.9
Ethnic group: Mixed or Multiple ethnic groups: 77.5
Ethnic group: White: 101.9
Cannot speak English well or at all: 34.8
No religion: 91.8
Christian: 106.6
Other religion: 70.0
Never married and never registered a civil partnership: 83.5
Married or in a registered civil partnership: 110.7
Separated or divorced: 91.3
One-person household: 86.3
Families with no children: 108.2
Families with dependent children: 102.0
All household members have the same ethnic group: 109.6
Lives in a communal establishment: 56.1
Address 1 year ago is the same as the address of enumeration: 101.8
Detached house or bungalow: 137.4
Semi-detached house or bungalow: 116.1
Terraced (including end-terrace) house or bungalow: 47.7
Flat maisonette or apartment: 31.0
Ownership or shared ownership: 111.7
Social rented: 39.7
Private rented: 79.8
SIR: 77.2
Provides unpaid care: 102.7
2 or more cars or vans in household: 117.8
Highest level of qualification: Level 1- 2 or Apprenticeship: 100.6
Highest level of qualification: Level 3 qualifications: 103.8
Highest level of qualification: Level 4 qualifications or above: 113.1
Hours worked: Part-time: 95.7
Hours worked: Full-time: 102.3
NS-SeC: L15 Full-time students: 94.1
SOC: 1. Managers directors and senior officials: 114.0
SOC: 2. Professional occupations: 109.8
SOC: 3. Associate professional and technical occupations: 106.9
SOC: 4. Administrative and secretarial occupations: 105.4
SOC: 5. Skilled trades occupations: 100.9
SOC: 6. Caring leisure and other service occupations: 90.7
SOC: 7. Sales and customer service occupations: 91.8
SOC: 8. Process plant and machine operatives: 90.5
SOC: 9. Elementary occupations: 82.8
Economically active: Unemployed: 72.0
In the style of a commercial geodemographic classification; create a cluster name
that would summarise the created geodemographic pen portraits. The names should capture as many
different characteristics contained within the description as possible.
The cluster name should be no more than 3 words.
Return your response in JSON format with the structure:
{"cluster_key_1": {"name": "", "description": ""},
"cluster_key_2": {"name": "", "description": ""},...}Copy the result in here;
cluster_summaries = {
"A": {
"name": "Established Professional Residents",
"description": "This neighbourhood is characterised by an older demographic profile, with notably higher proportions of residents aged sixty-five and over, particularly those aged eighty-five and above who are represented at considerably elevated levels compared to the regional average. The area has a markedly high concentration of residents living in communal establishments, appearing at more than twice the regional rate. Housing stock is distinctively skewed towards flats, maisonettes, and apartments, which feature at substantially elevated levels, while detached properties also appear somewhat above the regional norm. The residential population shows a strong presence of one-person households, appearing at moderately elevated levels. The neighbourhood demonstrates an established, relatively settled character, with residents predominantly UK-born and overwhelmingly from a single ethnic background. The Black population is notably underrepresented, appearing at substantially lower levels than the regional average, while residents who cannot speak English well or at all are also significantly below regional norms. The area exhibits a professional character, with managers, directors, senior officials, and professional occupations represented at moderately elevated levels. Educational attainment leans towards higher qualifications, with Level 4 qualifications and above appearing at notably higher rates. Residents are more likely to be married or in registered civil partnerships, and somewhat more likely to be separated or divorced than the regional average. The neighbourhood shows lower proportions of families with dependent children and younger age groups, particularly those under five, who appear at moderately reduced levels. Despite the professional occupational profile, full-time students are somewhat underrepresented, and unemployment appears at lower levels than the region. The area has moderately elevated rates of private rental accommodation alongside ownership, suggesting a mixed tenure profile that accommodates both established homeowners and professional renters."
},
"B": {
"name": "Multicultural Urban Families",
"description": "This neighbourhood stands out for its remarkable ethnic diversity, with substantially elevated representation across multiple minority ethnic groups. Pakistani, Black, Bangladeshi, and Other Asian populations all appear at considerably higher levels than the regional average, with some groups represented at nearly three times the regional rate. Chinese and Indian populations are also present at notably elevated levels, while the White population is moderately below the regional average. This diversity is reflected in the country of birth data, with residents born in Africa appearing at more than twice the regional rate, and those from both EU and non-EU European countries substantially overrepresented. The neighbourhood faces significant linguistic challenges, with residents who cannot speak English well or at all appearing at nearly three times the regional rate. The area has a younger demographic profile, with children under five represented at moderately elevated levels, while older residents, particularly those aged eighty-five and over, appear at substantially reduced rates. The housing landscape is dominated by terraced houses and flats, both appearing at considerably elevated levels, while detached and semi-detached properties are somewhat underrepresented. Social rented accommodation features prominently at substantially higher rates, alongside moderately elevated private rental levels, while ownership rates fall notably below the regional average. Vehicle ownership is considerably lower, with households having two or more cars appearing at substantially reduced levels. The occupational structure skews towards elementary occupations, which appear at moderately elevated rates, while managers, directors, and senior officials are somewhat underrepresented. Unemployment appears at considerably higher levels than the regional average. The neighbourhood shows elevated proportions of part-time workers and full-time students. Despite the diverse population, families with dependent children appear at levels close to the regional average, while one-person households are moderately elevated. Religious adherence is notable, with followers of non-Christian religions appearing at moderately elevated levels."
},
"C": {
"name": "Working Family Terraces",
"description": "This neighbourhood presents a working-class character with a predominantly UK-born, White population that closely mirrors regional averages. The area is notably less diverse than the region, with most minority ethnic groups substantially underrepresented, particularly Pakistani populations who appear at less than half the regional rate. Black, Bangladeshi, Chinese, and Indian populations are all present at considerably reduced levels. Residents born in Africa, non-EU Europe, and EU countries all appear at notably lower rates than the regional average. The demographic profile shows a family-oriented character, with children under five and those aged five to fourteen both appearing at moderately elevated levels, while residents aged eighty-five and over are present at somewhat reduced rates. Families with dependent children feature at moderately higher levels than the region. The housing stock is heavily weighted towards terraced properties, which appear at substantially elevated rates, while detached houses and flats are both considerably underrepresented. Social rented accommodation is present at considerably elevated levels, while ownership rates remain close to regional norms. The communal establishment population is dramatically underrepresented, appearing at nearly half the regional rate. The neighbourhood's occupational profile reveals a working-class character, with elementary occupations, process plant and machine operatives, sales and customer service occupations, and caring service occupations all appearing at moderately elevated levels. Conversely, managers, directors, senior officials, and professional occupations are both somewhat underrepresented. Educational attainment trends lower, with Level 4 qualifications considerably below regional rates, while Level 1-2 qualifications appear at moderately elevated levels. Unemployment is present at moderately higher rates than the regional average. The area shows relative residential stability, with most residents living at the same address as one year prior, and households predominantly comprising members from the same ethnic group."
},
"D": {
"name": "Student Cosmopolitan Flats",
"description": "This neighbourhood exhibits a distinctly transient, young adult character, overwhelmingly dominated by residents living in communal establishments at more than five times the regional rate. The area shows a dramatic absence of children and older residents, with those aged under five appearing at less than two-thirds the regional rate, those aged five to fourteen at less than half, and those aged eighty-five and over at roughly one-quarter of regional levels. Middle-aged residents are also considerably underrepresented. The population is remarkably diverse and internationally oriented, with residents born outside the UK substantially overrepresented. Those born in non-EU European countries appear at more than three times the regional rate, while African and EU-born residents are also present at considerably elevated levels. UK-born residents are notably underrepresented. This international character is reflected in exceptional ethnic diversity, with Pakistani, Indian, Chinese, Black, Bangladeshi, Other Asian, and Mixed ethnic group populations all appearing at substantially elevated levels, many at roughly three times the regional rate. The White population is moderately below regional averages. Language barriers are significant, with residents who cannot speak English well or at all appearing at roughly twice the regional rate. Full-time students are present at substantially elevated rates, nearly one and a half times the regional average, explaining much of the neighbourhood's character. The housing stock is dominated by flats, maisonettes, and apartments at more than twice the regional rate, while traditional houses—detached, semi-detached, and terraced—are all dramatically underrepresented. Private rental accommodation is substantially elevated, while ownership rates are notably below regional levels. The area shows high residential turnover, with residents far less likely to be living at the same address as one year prior. Educational qualifications trend higher, with Level 3 and particularly Level 4 qualifications above regional rates, while lower-level qualifications are substantially underrepresented. Professional occupations appear at moderately elevated levels, while skilled trades and process plant operatives are considerably below regional averages. Never-married individuals are substantially overrepresented, while married couples and families with dependent children appear at considerably reduced rates."
},
"E": {
"name": "Suburban Family Homeowners",
"description": "This neighbourhood represents an affluent, predominantly White British suburban character. The population is overwhelmingly UK-born, with residents from EU countries, non-EU Europe, and Africa all appearing at substantially reduced levels compared to the regional average. Ethnic diversity is notably low, with Black populations present at less than half the regional rate, and Pakistani, Bangladeshi, Other Asian, and Mixed ethnic group populations all considerably underrepresented. Language barriers are virtually absent, with residents who cannot speak English well or at all appearing at roughly one-third of the regional rate. The area exhibits strong ethnic homogeneity, with households where all members share the same ethnic group appearing at moderately elevated levels. The demographic profile skews slightly older, with residents aged sixty-five to eighty-four and those aged eighty-five and over both appearing at moderately elevated rates. The housing landscape is characterised by owner-occupation at moderately elevated levels, with detached houses substantially overrepresented and semi-detached properties also appearing above regional averages. Conversely, terraced houses appear at less than half the regional rate, while flats are dramatically underrepresented at roughly one-third of regional levels. Social rented accommodation is substantially below regional averages, as is private rental accommodation. The area demonstrates affluence through vehicle ownership, with households possessing two or more cars appearing at moderately elevated rates. The occupational structure reflects professional and managerial employment, with managers, directors, senior officials, professional occupations, and associate professional and technical occupations all appearing at moderately elevated levels. Elementary occupations are somewhat underrepresented. Educational attainment is strong, with Level 4 qualifications and above appearing at moderately elevated rates. Employment rates are favourable, with unemployment substantially below regional levels at roughly three-quarters of the regional rate. The neighbourhood shows a family-oriented character, with married couples moderately overrepresented and never-married individuals somewhat underrepresented. Families with no children appear at moderately elevated levels. One-person households and communal establishment residents are both substantially below regional averages, reinforcing the family-oriented suburban character."
}
}
cluster_descriptions_df = pd.DataFrame.from_dict(cluster_summaries, orient='index')
#pretty print the descriptions (break lines for readability)
for cluster, row in cluster_descriptions_df.iterrows():
print(f"Cluster {cluster} - {row['name']}:\n")
description = row['description']
#break into lines of max 80 characters
import textwrap
wrapped_description = textwrap.fill(description, width=70)
print(wrapped_description, "\n\n")Cluster A - Established Professional Residents:
This neighbourhood is characterised by an older demographic profile,
with notably higher proportions of residents aged sixty-five and over,
particularly those aged eighty-five and above who are represented at
considerably elevated levels compared to the regional average. The
area has a markedly high concentration of residents living in communal
establishments, appearing at more than twice the regional rate.
Housing stock is distinctively skewed towards flats, maisonettes, and
apartments, which feature at substantially elevated levels, while
detached properties also appear somewhat above the regional norm. The
residential population shows a strong presence of one-person
households, appearing at moderately elevated levels. The neighbourhood
demonstrates an established, relatively settled character, with
residents predominantly UK-born and overwhelmingly from a single
ethnic background. The Black population is notably underrepresented,
appearing at substantially lower levels than the regional average,
while residents who cannot speak English well or at all are also
significantly below regional norms. The area exhibits a professional
character, with managers, directors, senior officials, and
professional occupations represented at moderately elevated levels.
Educational attainment leans towards higher qualifications, with Level
4 qualifications and above appearing at notably higher rates.
Residents are more likely to be married or in registered civil
partnerships, and somewhat more likely to be separated or divorced
than the regional average. The neighbourhood shows lower proportions
of families with dependent children and younger age groups,
particularly those under five, who appear at moderately reduced
levels. Despite the professional occupational profile, full-time
students are somewhat underrepresented, and unemployment appears at
lower levels than the region. The area has moderately elevated rates
of private rental accommodation alongside ownership, suggesting a
mixed tenure profile that accommodates both established homeowners and
professional renters.
Cluster B - Multicultural Urban Families:
This neighbourhood stands out for its remarkable ethnic diversity,
with substantially elevated representation across multiple minority
ethnic groups. Pakistani, Black, Bangladeshi, and Other Asian
populations all appear at considerably higher levels than the regional
average, with some groups represented at nearly three times the
regional rate. Chinese and Indian populations are also present at
notably elevated levels, while the White population is moderately
below the regional average. This diversity is reflected in the country
of birth data, with residents born in Africa appearing at more than
twice the regional rate, and those from both EU and non-EU European
countries substantially overrepresented. The neighbourhood faces
significant linguistic challenges, with residents who cannot speak
English well or at all appearing at nearly three times the regional
rate. The area has a younger demographic profile, with children under
five represented at moderately elevated levels, while older residents,
particularly those aged eighty-five and over, appear at substantially
reduced rates. The housing landscape is dominated by terraced houses
and flats, both appearing at considerably elevated levels, while
detached and semi-detached properties are somewhat underrepresented.
Social rented accommodation features prominently at substantially
higher rates, alongside moderately elevated private rental levels,
while ownership rates fall notably below the regional average. Vehicle
ownership is considerably lower, with households having two or more
cars appearing at substantially reduced levels. The occupational
structure skews towards elementary occupations, which appear at
moderately elevated rates, while managers, directors, and senior
officials are somewhat underrepresented. Unemployment appears at
considerably higher levels than the regional average. The
neighbourhood shows elevated proportions of part-time workers and
full-time students. Despite the diverse population, families with
dependent children appear at levels close to the regional average,
while one-person households are moderately elevated. Religious
adherence is notable, with followers of non-Christian religions
appearing at moderately elevated levels.
Cluster C - Working Family Terraces:
This neighbourhood presents a working-class character with a
predominantly UK-born, White population that closely mirrors regional
averages. The area is notably less diverse than the region, with most
minority ethnic groups substantially underrepresented, particularly
Pakistani populations who appear at less than half the regional rate.
Black, Bangladeshi, Chinese, and Indian populations are all present at
considerably reduced levels. Residents born in Africa, non-EU Europe,
and EU countries all appear at notably lower rates than the regional
average. The demographic profile shows a family-oriented character,
with children under five and those aged five to fourteen both
appearing at moderately elevated levels, while residents aged eighty-
five and over are present at somewhat reduced rates. Families with
dependent children feature at moderately higher levels than the
region. The housing stock is heavily weighted towards terraced
properties, which appear at substantially elevated rates, while
detached houses and flats are both considerably underrepresented.
Social rented accommodation is present at considerably elevated
levels, while ownership rates remain close to regional norms. The
communal establishment population is dramatically underrepresented,
appearing at nearly half the regional rate. The neighbourhood's
occupational profile reveals a working-class character, with
elementary occupations, process plant and machine operatives, sales
and customer service occupations, and caring service occupations all
appearing at moderately elevated levels. Conversely, managers,
directors, senior officials, and professional occupations are both
somewhat underrepresented. Educational attainment trends lower, with
Level 4 qualifications considerably below regional rates, while Level
1-2 qualifications appear at moderately elevated levels. Unemployment
is present at moderately higher rates than the regional average. The
area shows relative residential stability, with most residents living
at the same address as one year prior, and households predominantly
comprising members from the same ethnic group.
Cluster D - Student Cosmopolitan Flats:
This neighbourhood exhibits a distinctly transient, young adult
character, overwhelmingly dominated by residents living in communal
establishments at more than five times the regional rate. The area
shows a dramatic absence of children and older residents, with those
aged under five appearing at less than two-thirds the regional rate,
those aged five to fourteen at less than half, and those aged eighty-
five and over at roughly one-quarter of regional levels. Middle-aged
residents are also considerably underrepresented. The population is
remarkably diverse and internationally oriented, with residents born
outside the UK substantially overrepresented. Those born in non-EU
European countries appear at more than three times the regional rate,
while African and EU-born residents are also present at considerably
elevated levels. UK-born residents are notably underrepresented. This
international character is reflected in exceptional ethnic diversity,
with Pakistani, Indian, Chinese, Black, Bangladeshi, Other Asian, and
Mixed ethnic group populations all appearing at substantially elevated
levels, many at roughly three times the regional rate. The White
population is moderately below regional averages. Language barriers
are significant, with residents who cannot speak English well or at
all appearing at roughly twice the regional rate. Full-time students
are present at substantially elevated rates, nearly one and a half
times the regional average, explaining much of the neighbourhood's
character. The housing stock is dominated by flats, maisonettes, and
apartments at more than twice the regional rate, while traditional
houses—detached, semi-detached, and terraced—are all dramatically
underrepresented. Private rental accommodation is substantially
elevated, while ownership rates are notably below regional levels. The
area shows high residential turnover, with residents far less likely
to be living at the same address as one year prior. Educational
qualifications trend higher, with Level 3 and particularly Level 4
qualifications above regional rates, while lower-level qualifications
are substantially underrepresented. Professional occupations appear at
moderately elevated levels, while skilled trades and process plant
operatives are considerably below regional averages. Never-married
individuals are substantially overrepresented, while married couples
and families with dependent children appear at considerably reduced
rates.
Cluster E - Suburban Family Homeowners:
This neighbourhood represents an affluent, predominantly White British
suburban character. The population is overwhelmingly UK-born, with
residents from EU countries, non-EU Europe, and Africa all appearing
at substantially reduced levels compared to the regional average.
Ethnic diversity is notably low, with Black populations present at
less than half the regional rate, and Pakistani, Bangladeshi, Other
Asian, and Mixed ethnic group populations all considerably
underrepresented. Language barriers are virtually absent, with
residents who cannot speak English well or at all appearing at roughly
one-third of the regional rate. The area exhibits strong ethnic
homogeneity, with households where all members share the same ethnic
group appearing at moderately elevated levels. The demographic profile
skews slightly older, with residents aged sixty-five to eighty-four
and those aged eighty-five and over both appearing at moderately
elevated rates. The housing landscape is characterised by owner-
occupation at moderately elevated levels, with detached houses
substantially overrepresented and semi-detached properties also
appearing above regional averages. Conversely, terraced houses appear
at less than half the regional rate, while flats are dramatically
underrepresented at roughly one-third of regional levels. Social
rented accommodation is substantially below regional averages, as is
private rental accommodation. The area demonstrates affluence through
vehicle ownership, with households possessing two or more cars
appearing at moderately elevated rates. The occupational structure
reflects professional and managerial employment, with managers,
directors, senior officials, professional occupations, and associate
professional and technical occupations all appearing at moderately
elevated levels. Elementary occupations are somewhat underrepresented.
Educational attainment is strong, with Level 4 qualifications and
above appearing at moderately elevated rates. Employment rates are
favourable, with unemployment substantially below regional levels at
roughly three-quarters of the regional rate. The neighbourhood shows a
family-oriented character, with married couples moderately
overrepresented and never-married individuals somewhat
underrepresented. Families with no children appear at moderately
elevated levels. One-person households and communal establishment
residents are both substantially below regional averages, reinforcing
the family-oriented suburban character.
While the LLM generated names and descriptions are a very useful starting point, it is important to review the outputs carefully both for accuracy, and that they make sense in the context of your specific region and purpose. Any use of LLMs in a production context would need to invove a human in the loop to review the outputs and a ground truthing exercise to ensure the outputs are valid.
cluster_descriptions_df| name | description | |
|---|---|---|
| A | Established Professional Residents | This neighbourhood is characterised by an olde... |
| B | Multicultural Urban Families | This neighbourhood stands out for its remarkab... |
| C | Working Family Terraces | This neighbourhood presents a working-class ch... |
| D | Student Cosmopolitan Flats | This neighbourhood exhibits a distinctly trans... |
| E | Suburban Family Homeowners | This neighbourhood represents an affluent, pre... |
Save Results
Lets save the results to file for use in GIS software or to format for sharing.
cluster_descriptions_df.to_csv("outputs/cluster_descriptions.csv")
gdf = oas_region.merge(supergrouped_variable_df, left_index=True, right_index=True, how='left')
#save to gpkg
gdf.to_file("outputs/clustered_geodataframe.gpkg", layer="clusters", driver="GPKG")Hierarchical Subclustering
We often want to perform a finer level of clustering to capture more detailed patterns in the data. For OAC the top level “supergroup” clusters are split further into groups and subgroups by applying the above process iteratively. This process is referred to as top down clustering. This has the advantage of allowing more clusters to be created without needing to consider all clusters at once. It also allows for more interpretable clusters as the subclusters are nested within the broader supergroup clusters.
Selecting the Number of Subclusters
We can use clustergrams again to select the number of subclusters for each supergroup. We create clustergrams for each supergroup and select the number of subclusters based on the same principles as before.
def create_subcluster_clustergrams(output_df, num_clusters, n_init=1):
"""
Generate and save clustergrams for each supercluster.
This function loops through the existing clusters and creates a clustergram
for each
Parameters:
output_df (pd.DataFrame): DataFrame containing cluster assignments.
num_clusters (int): The total number of clusters to iterate over.
n_init (int, optional): Number of times K-means runs with different centroid seeds.
Defaults to 1 for quick testing.
"""
save_dir = "outputs/plots" #directory to save the clustergrams
os.makedirs(save_dir, exist_ok=True) # Ensure save directory exists
cluster_labels = np.sort(output_df["cluster"].unique())
print(cluster_labels)
for cluster_label in cluster_labels:
# Select rows corresponding to the current cluster, dropping the 'cluster' column
cluster_df = output_df.query("cluster == @cluster_label").drop(columns='cluster')
print(f"Cluster: {cluster_label,cluster_summaries[cluster_label]['name']}, {len(cluster_df)} geographies in cluster")
if cluster_df.empty:
print(f"Skipping cluster {cluster_label} as it has no data.")
continue
# Define save location
save_loc = os.path.join(save_dir, f"subcluster_clustergram_cluster{cluster_label}.png")
print(f"Saving clustergram to {save_loc}")
# Generate clustergram
cgram_sub = Clustergram(range(1, 10), n_init=n_init, random_state=random_seed,verbose=False)
cgram_sub.fit(cluster_df) # Fit model to data
cgram_sub.plot() # Generate plot
plt.suptitle(f"Clustergram for Cluster {cluster_label} - {cluster_summaries[cluster_label]['name']}")
plt.savefig(save_loc) # Save figure
plt.show() # Display plot
# Example usage
create_subcluster_clustergrams(supergrouped_variable_df, num_clusters, n_init=50)
['A' 'B' 'C' 'D' 'E']
Cluster: ('A', 'Established Professional Residents'), 804 geographies in cluster
Saving clustergram to outputs/plots/subcluster_clustergram_clusterA.png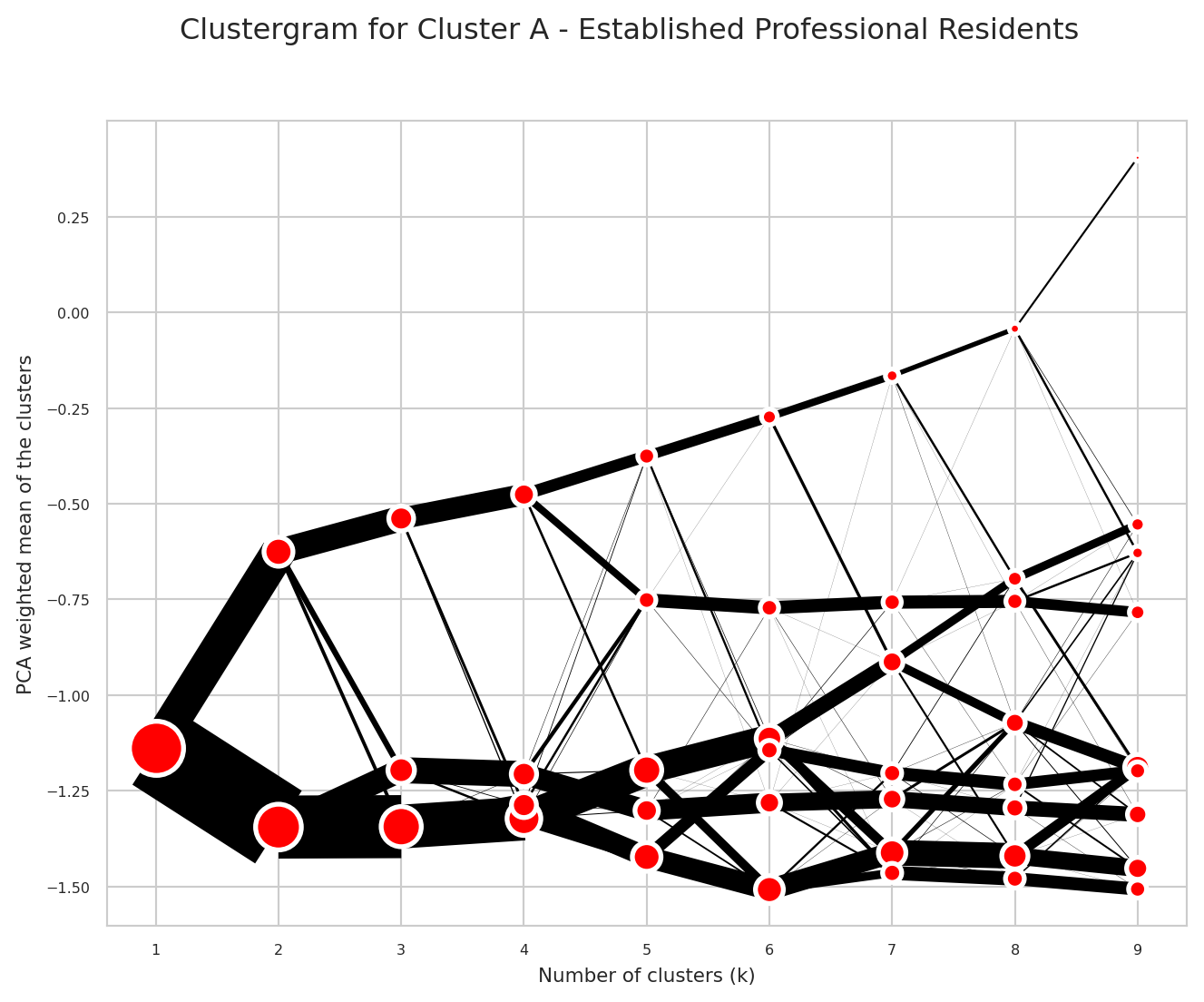
Cluster: ('B', 'Multicultural Urban Families'), 737 geographies in cluster
Saving clustergram to outputs/plots/subcluster_clustergram_clusterB.png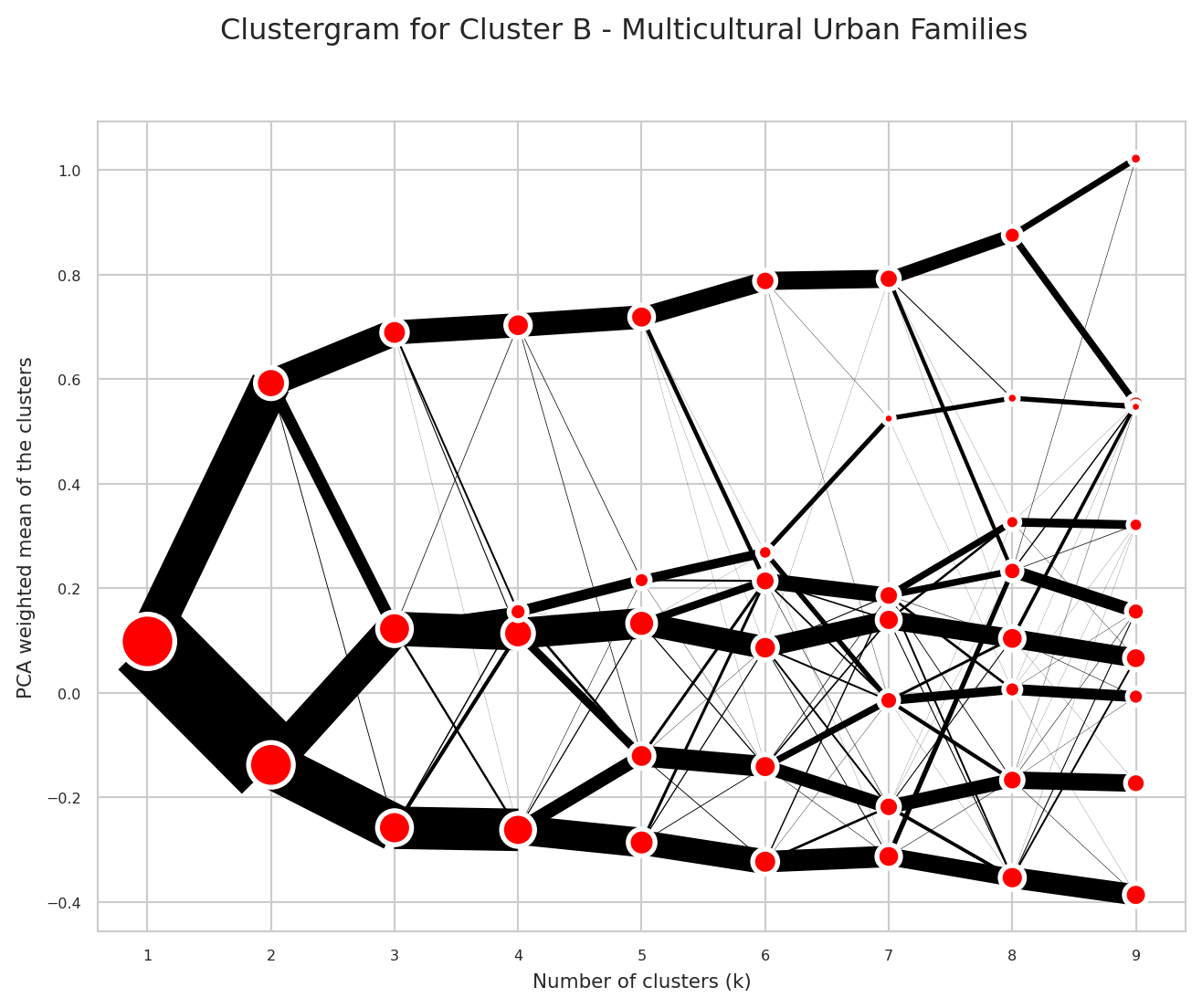
Cluster: ('C', 'Working Family Terraces'), 1875 geographies in cluster
Saving clustergram to outputs/plots/subcluster_clustergram_clusterC.png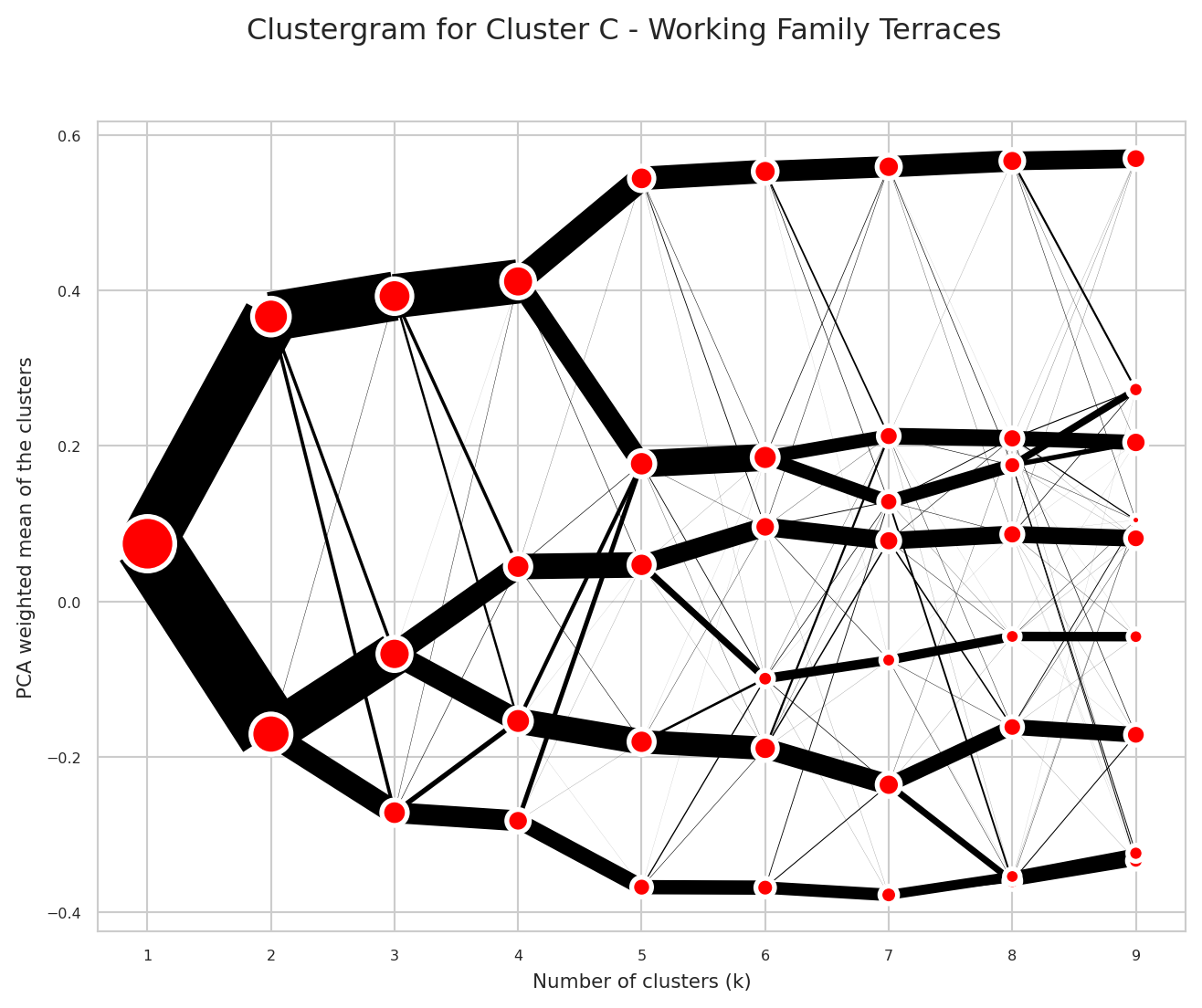
Cluster: ('D', 'Student Cosmopolitan Flats'), 192 geographies in cluster
Saving clustergram to outputs/plots/subcluster_clustergram_clusterD.png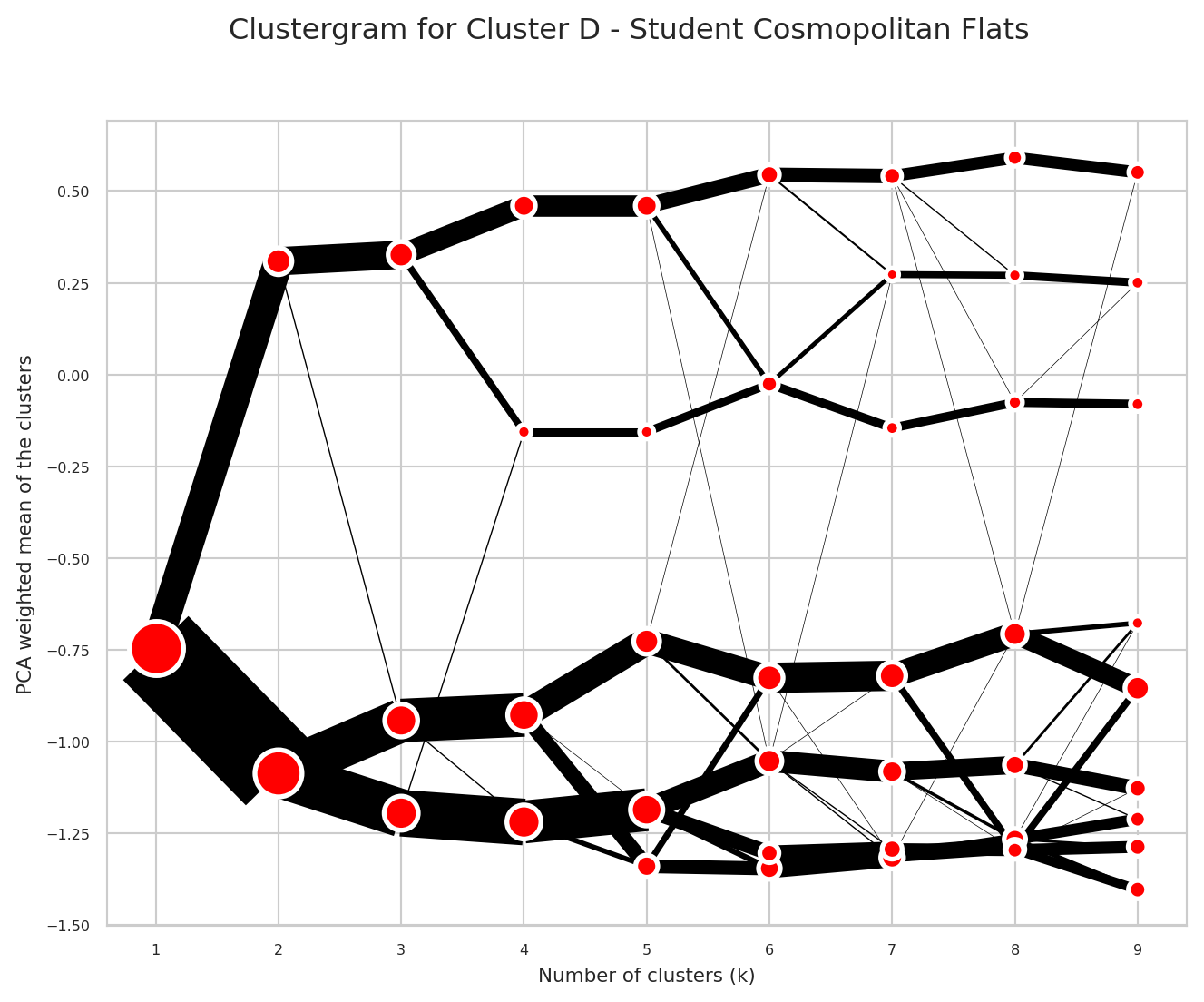
Cluster: ('E', 'Suburban Family Homeowners'), 1650 geographies in cluster
Saving clustergram to outputs/plots/subcluster_clustergram_clusterE.png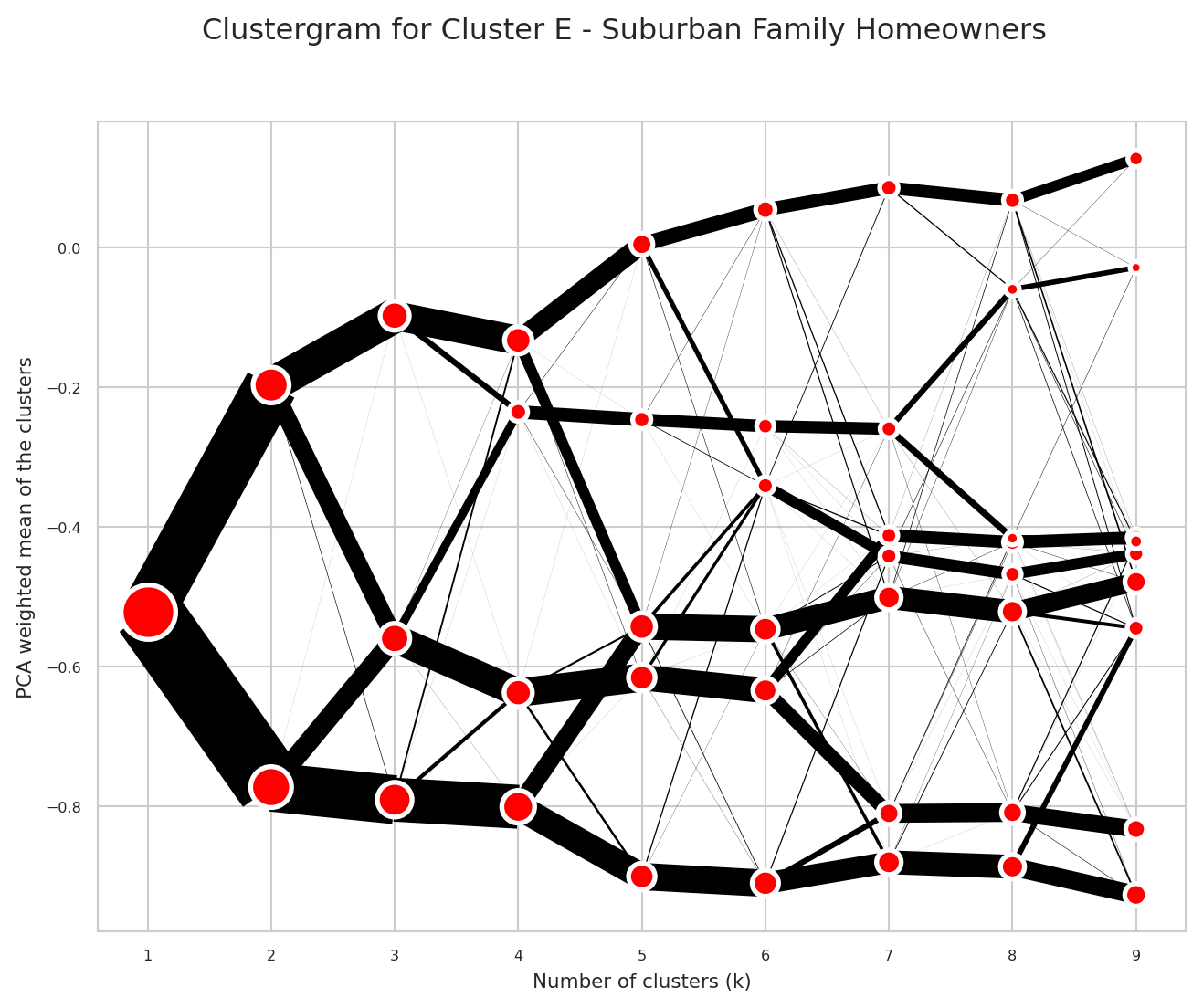
Run the subclustering
We can now select the number of subclusters to split each of the supergroups into using the clustergrams above. The length of the list must match num_clusters (the number of supergroups).
subcluster_nums = [3, 3, 4, 3, 3]
def run_subclustering(input_df: pd.DataFrame, subcluster_nums: list, num_clusters: int, n_init: int = 1) -> pd.DataFrame:
"""
Runs subclustering for each supergroup using KMeans and returns a modified DataFrame with subcluster labels.
Parameters:
- output_df (pd.DataFrame): The original DataFrame containing data and cluster assignments.
- subcluster_nums (list): A list specifying the number of subclusters to split each supergroup into.
- num_clusters (int): The total number of supergroups.
- n_init (int, optional): The number of times KMeans will be initialized. Defaults to 1.
Returns:
- pd.DataFrame: A new the output dataFrame with an added 'subcluster' column.
"""
cluster_labels = np.sort(input_df["cluster"].unique())
print(f"Cluster labels found: {cluster_labels}")
if len(subcluster_nums) != len(cluster_labels):
raise ValueError(f"Length of subcluster_nums ({len(subcluster_nums)}) does not match num_clusters ({len(cluster_labels)}).")
# Work on a copy of the DataFrame to prevent unintended modifications
df = input_df.copy()
for cluster, num_subclusters in zip(cluster_labels, subcluster_nums):
print(f"Clustering supergroup {cluster,cluster_summaries[cluster]['name']} into {num_subclusters} subclusters.")
# Select rows corresponding to the current cluster, drop the cluster column before clustering
cluster_df = input_df.query("cluster == @cluster").drop(columns='cluster').copy()
# Run KMeans clustering for the selected supergroup
subcluster_output_df = cluster_df.copy()
kmeans_sub = KMeans(n_clusters=num_subclusters, init="random", random_state=random_seed, n_init=n_init)
subcluster_output_df['cluster'] = kmeans_sub.fit_predict(cluster_df)
# Combine names
subcluster_output_df['subcluster'] = [str(cluster) + str(i) for i in subcluster_output_df['cluster']]
# Update the modified DataFrame with subclustering results
df.loc[cluster_df.index, 'subcluster'] = subcluster_output_df['subcluster']
# Save the final output
df[["cluster","subcluster"]].to_csv("outputs/subgroups_clusteroutput.csv")
print("Final output saved to outputs/subgroups_clusteroutput.csv")
return df # Return the modified DataFrame with clusters and subclusters
subgrouped_variable_df = run_subclustering(supergrouped_variable_df, subcluster_nums, num_clusters=num_clusters, n_init=1)Cluster labels found: ['A' 'B' 'C' 'D' 'E']
Clustering supergroup ('A', 'Established Professional Residents') into 3 subclusters.
Clustering supergroup ('B', 'Multicultural Urban Families') into 3 subclusters.
Clustering supergroup ('C', 'Working Family Terraces') into 4 subclusters.
Clustering supergroup ('D', 'Student Cosmopolitan Flats') into 3 subclusters.
Clustering supergroup ('E', 'Suburban Family Homeowners') into 3 subclusters.
Final output saved to outputs/subgroups_clusteroutput.csvVisualise and save the results
# --- Calculate percentage difference (subclusters vs cluster means) ---
global_means = subgrouped_variable_df[features].mean()
subcluster_means = subgrouped_variable_df.groupby(["cluster", "subcluster"]).mean(numeric_only=True)
# percentage difference: subcluster relative to global means
pct_diff_sub = (subcluster_means/ global_means)*100
pct_display_df_sub = pct_diff_sub.T
#replace the column MultiIndex with a single level index with "cluster-subcluster" format and swap in the cluster names from cluster_summaries
pct_display_df_sub.columns = [f"{cluster_summaries[c[0]]['name']}-{c[1]}" for c in pct_display_df_sub.columns]
# build customdata for hover (human names repeated across cluster–subcluster combos)
human_names = pct_display_df_sub.index.map(lambda e: encoding_to_name.get(e, e)).values
customdata_pct_sub = np.tile(human_names.reshape(-1, 1), (1, pct_display_df_sub.shape[1]))
# --- Heatmap (percentage difference: subcluster vs cluster mean) ---
fig_pct_sub = px.imshow(
pct_display_df_sub,
color_continuous_scale="RdYlGn",
origin="lower",
aspect="auto",
labels=dict(x="Subcluster", y="Feature (encoding)", color="% of cluster mean"),
zmin=0,
zmax=200
)
# attach customdata and set hover
fig_pct_sub.data[0].customdata = customdata_pct_sub
fig_pct_sub.update_traces(
hovertemplate="Subcluster: %{x}<br>Encoding: %{y}<br>Name: %{customdata}<br>% of Cluster Mean: %{z:.1f}%<extra></extra>",
zmid=100 # centre colours on 100%
)
fig_pct_sub.update_layout(
title="Subcluster Profiles (% of Cluster Mean)",
xaxis_title="Subcluster",
yaxis_title="Feature (encoding)",
height=800
)
# get mapping of column → cluster
col_clusters = [col.split("-")[0] for col in pct_display_df_sub.columns]
# find where cluster changes (between adjacent columns)
boundaries = [
i + 0.5 for i in range(len(col_clusters) - 1)
if col_clusters[i] != col_clusters[i + 1]
]
# add vertical lines at these boundaries
for b in boundaries:
fig_pct_sub.add_vline(
x=b, line_width=2, line_dash="dash", line_color="black"
)
fig_pct_sub.show()Save the results to file for use in GIS software or to format for sharing:
#merge the geometry column from oas_region to subgrouped_variable_df to make a geodataframe
gdf = oas_region.merge(subgrouped_variable_df , left_index=True, right_index=True, how='left')
#save to file
gdf.to_file("outputs/subclusters_geodataframe.gpkg", layer='subclusters', driver="GPKG")